AVEO-VEDA: Hybrid Programming for the NEC Vector Engine
Jul 14, 2021, Nicolas Weber, NEC Laboratories Europe, Erich Focht, NEC Deutschland HPCE
Hybrid programming is a state of the art method for incorporating compute accelerators such as GPUs or vector processors into applications that run on a host system. The main reason for hybrid programming is that compute accelerators are well suited for compute and memory heavy tasks but perform poorly in control flow dominated code sections. Therefore latter are usually executed on CPUs while the compute heavy parts are offloaded to accelerators. This article introduces the low-level AVEO and high-level VEDA programming APIs for programming the NEC SX-Aurora TSUBASA, also called Vector Engine (VE).
1. Another|Alternative|Awesome VE Offloading (AVEO)
Vector Engine Offloading (VEO) was the first hybrid programming API for the NEC SX-Aurora TSUBASA. It featured asynchronous kernel calls and memcopies. However, it relied on the system DMA engine which causes high latencies when calling kernels and low memcopy bandwidth.
Therefore AVEO was created as successor to VEO. It uses the same API but significantly improves kernel call latencies (see Figure 1) and memcopy bandwidth (see Figure 2). This is achieved by utilizing the user DMA engine and huge page data segments for improved memcopy bandwidth.
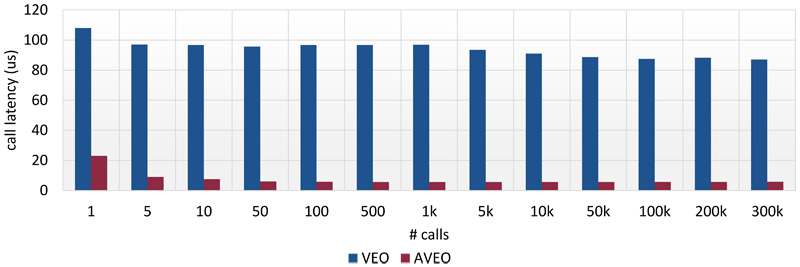 Figure 1: Comparison of call latency between VEO and AVEO, lower is better.
Figure 1: Comparison of call latency between VEO and AVEO, lower is better.Figure 1: Comparison of call latency between VEO and AVEO, lower is better.
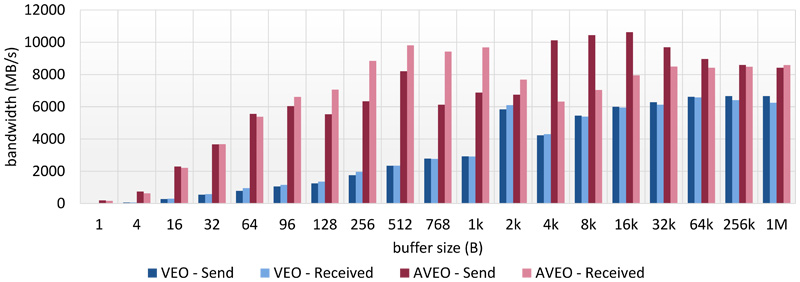 Figure 2: Comparison of memcopy bandwidth between VEO and AVEO, higher is better.
Figure 2: Comparison of memcopy bandwidth between VEO and AVEO, higher is better.Figure 2: Comparison of memcopy bandwidth between VEO and AVEO, higher is better.
The SX-Aurora Vector Engine (VE) runs without any operating system (OS) support on VE card. OS support is provided for VE native programs by VEOS, a daemon that runs on the host system. It interacts with the VE program's pseudo-process which is the host-side VE program loader that acts as system call and exception handler for the life time of a VE process. With no actual OS support for offloading, AVEO leverages these mechanisms and connects host-side programs with temporary VE-side offload kernel execution dispatchers, instantiated on the user's behalf for just the lifetime of their programs, as depicted in Figure 3.
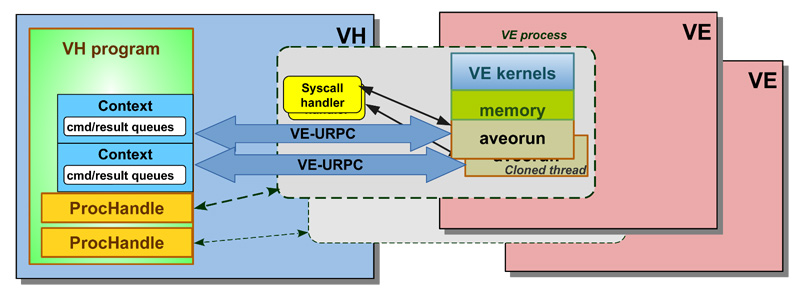
Figure 3: Architecture of AVEO. Host (VH) side processes are connected to temporary aveorun VE side kernel dispatchers through an RPC layer using user DMA.
Unlike other accelerators, offloaded VE kernels can use any system calls. The VE side kernel dispatcher process can be attached by the native VE gdb debugger as well as use all native VE program performance analysis tools.
To enable Hybrid MPI, AVEO introduced so-called Hybrid pointers (HMEM). These can be used with the NECMPI to develop hybrid distributed MPI applications that allow to utilize the SX-Aurora together with the host's CPU.
Compared to other APIs such as CUDA, OpenCL, SYCL or HIP, AVEO's API is much more low level. This results in somewhat verbose function calls, but also simplifies extending AVEO with new functionality.
2. Vector Engine Driver API (VEDA)
VEDA is an API inspired by the widely used CUDA Driver API. It builds upon AVEO and enables easy porting existing CUDA (and other hybrid) applications to VE. VEDA uses CUDA's design principles and maps these onto the execution model of AVEO. It supports multiple devices, NUMA nodes, asynchronous execution queues, and many more closely mirroring CUDA's best practices that have been tried and tested for over a decade.
Similar to CUDA, VEDA enumerates the physical devices and NUMA nodes starting from zero, whereby NUMA nodes have always adjacent indices. The environmental variable VEDA_VISIBLE_DEVICES determines which devices should be visible within the application. In contrast to CUDA, VEDA only supports a single device context at a time, which maintains all loaded libraries/modules and allocations.
The context can be generated in two different modes: VEDA_CONTEXT_MODE_OMP (default) and VEDA_CONTEXT_MODE_SCALAR. The first mode creates one stream (execution queue) that controls all threads through OpenMP. The second mode creates one stream per core, allowing to directly address each core separately from within the host.
In contrast to CUDA, the VE's memory allocator is operated by the device itself which gives VEDA the Opportunity of enabling asynchronous memory allocations from the host. This can reduce unnecessary synchronizations between the host and the device (see Figure 4).
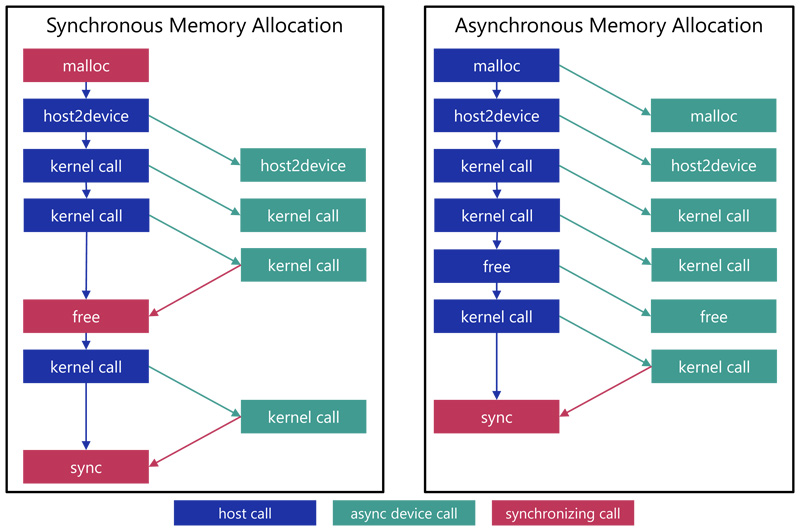
Figure 4: Example of synchronous versus asynchronous memory allocation. As can be seen, the application requires no explicit synchronizations except waiting for the execution queue to finish.
If VEDA pointers are allocated with a size of 0, only a virtual pointer will be created that can be allocated later using vedaMemAlloc(...) inside the device code. This enables to model execution graphs, without the need to know the required size before calling the device code. Virtual pointers behave identical to normal pointers, i.e. they can be dereferenced using offsets A = B + offset or A = &B[offset].
To summarize VEDA: It extends the functionality of AVEO applications by supporting asynchronous and delayed memory allocations, device to device transfers and the opportunity to access device information and sensor readings, e.g., temperature and power consumption.
2.1 Compiling VEDA Applications
VEDA includes an CMake extension that enables to compile the VEDA host and device code within a single CMake build system. The VEDA device code needs to be written in NCC SIMD dialect. SIMT-like programming is not supported yet. Also host and device code need to be written in separate files. To enable VEDA in CMake CMAKE_MODULE_PATH needs to be set to the VEDA directory, the languages VEDA_C, VEDA_CXX or VEDA_Fortran need to be enabled and the device source code file extensions need to be prefixed with v as in filename.vcpp. Afterwards, the entire compilation and linking process is automatically handled by CMake.
In addition to compiling hybrid VEDA applications, VEDA's CMake also supports compileing native applications. By enabling the languages VE_C, VE_CXX, or VE_Fortran, all *.c, *.vcpp, or *.vf files are compiled and linked to native VE applications and libraries. Alternatively –D /path/to/veda/cmake/InjectVE.cmake can be passed as argument to CMake to automatically convert an existing CMake CPU project into an VE project without changing the code or renaming any files.
2.2 VEDA Device Information
The NVIDIA driver includes an information tool called nvidia-smi. Similar to this VEDA provides veda-smi to display available devices (see Listing 1). veda-smi reacts to the VEDA_VISIBLE_DEVICES environmental variable and only shows information about the selected devices. Other than nvidia-smi, veda-smi displays correct device ids that developers may immediately use in their code.

Listing 1: Example output of veda-smi for a single VE10B NUMA node.
3. How to get started with AVEO/VEDA?
Installing AVEO and VEDA can be easily done using YUM (yum install veoffload-aveo or yum install veda-0.10). In case you want to build these by yourself or your there is no suitable package for your system, you can clone the source code from github.com/sx-aurora/aveo or github.com/sx-aurora/veda respectively and follow the compilation instructions stated on the Github project page.
More information on AVEO and VEDA is found on their corresponding Github project pages.
- The product and service names on this website are trademarks or registered trademarks of either NEC Corporation, NEC Group companies or other companies respectively.