How vector computer contributes to seismic applications
Jul 1, 2021 Masashi Ikuta (Business Development Manager) AI Platform Division, NEC Corporation
This technical description will discuss about HPC for oil and gas applications and how vector computer can contribute to deliver high sustained performance.
The figure below illustrates the exploration and production value chain and role of HPC, AI, and Data Analytics in each step.
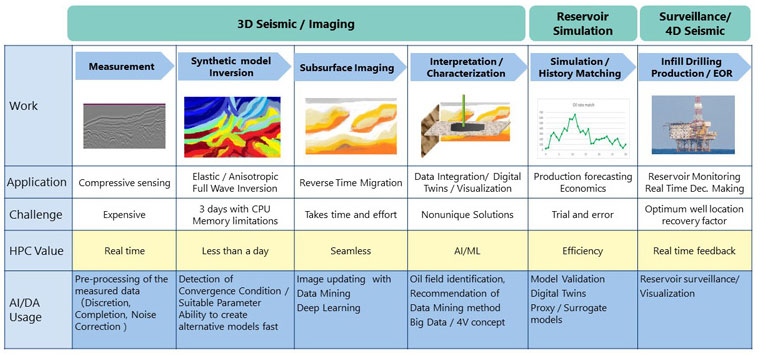 E&P Value Chain and HPC / AI / DA Role
E&P Value Chain and HPC / AI / DA RoleEverything starts from measurement using sensors. And that would be followed by modeling and subsurface imaging which is about so called FWI(Full Waveform Inversion) and RTM(Reverse Time Migration). The challenge here is that these operations can move from matter of few hours to even matter of few days. But if we can do the operation much faster with the help of HPC/AI/Machine Learning or mix of these, there would be a huge value added because we would be able to do things more seamless and make decisions faster, or understand how things are moving forward more accurately. From oil company point of view, this means you can improve success rate and reduce failure cost or delay cost. It means faster to revenue.
Same is true for reservoir simulation. If we can do more reservoir simulations then we can pick up the right one from larger ensemble of our simulation models by doing so called history matching. You can increase recovery factor and thus, increase revenue.
And basically what should be highlighted here is that each step of this whole operation involves a lot of data and requires a lot of high performance computing with the help of AI, ML, and Data Analytics.
But it's been a while since people started to say Moore's law is coming to an end. Is this true? Let's think about this looking into the figure below.
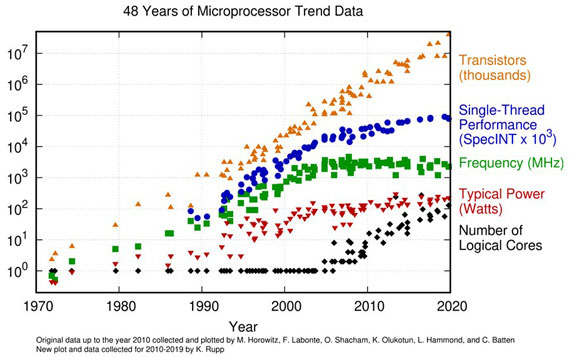 Is the Moore's Law over?
Is the Moore's Law over?When we look at this figure, we can understand that the number of transistors (the orange dots) continue to grow. But if we look at the blue dots, we can understand that thread performance have reached a plateau. And we can see that the number of logical cores (the black dots) is increasing. So, the fact is that we are having more and more cores, but each core's performance is no longer increasing.
This reminds us what late Seymour Cray asked. The father of supercomputing asked, "If you were plowing a field, which would you rather use: Two strong oxen or 1024 chickens?"
 Seymour Cray (the father of the Supercomputer) asked;
Seymour Cray (the father of the Supercomputer) asked;Fundamentally, he asked "Do you want more and more cores?" Or we can elaborate this like "Can you use so many cores efficiently and gain performance?" The answer to his question depends on what kind of applications we run. And Seymour Cray believed two oxen is more efficient and easy to gain performance in many cases, and thus he designed and developed vector computers.
But what is vector computer, or vector processor? This can be explained by comparing it with other architecture such as general processor (or scalar processor) and GPGPU.
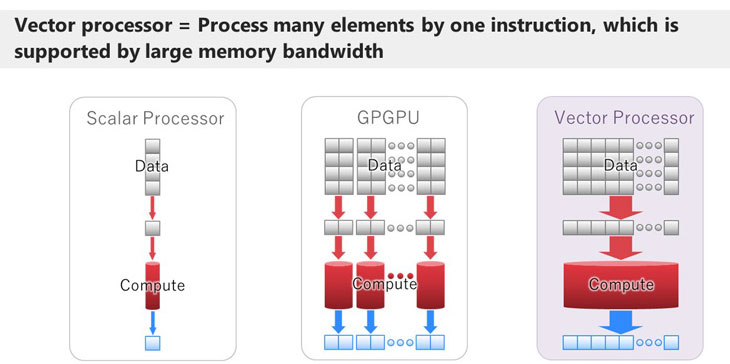 Scalar Processor, GPGPU, Vector Processor
Scalar Processor, GPGPU, Vector ProcessorA scalar processor core computes relatively small piece of data at one time. And nowadays scalar processors have many cores in one processor. GPGPU have massive number of cores, or many sets of cores. They have a stronger set of cores and many of those. Thus, they can compute more data at one time and output more results at one time. On the other hand, vector processors can compute many elements (which is called vector or array) by one instruction. So, vector processors have very powerful cores. And to feed many elements to the processor core, vector machines have large memory bandwidth. And as you know, it is often the case that vector or array is the core part of scientific computation and thus, vector is suited for scientific simulations.
But you might say scalar processors have feature called SIMD (Single Instruction Multiple Data). What is the difference between SIMD and Vector?
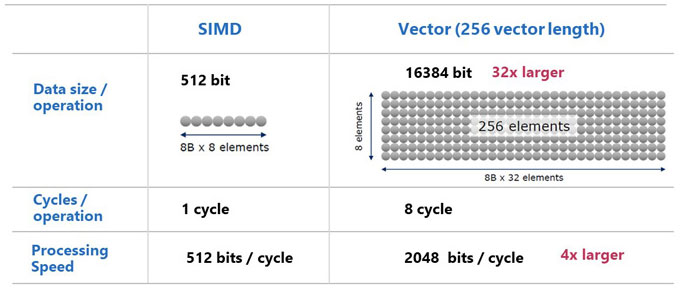 SIMD (Single Instruction Multiple Data) vs Vector
SIMD (Single Instruction Multiple Data) vs VectorThe answer is data size. For example, AVX which is a vector feature for x86 processors can handle 512 bit (8 x 8bit elements) at one time. But in NEC Vector computer, it can process more than 16 thousands bits (256 x 8bit elements) at one time. The figure below illustrates the architecture of SX-Aurora TSUBASA which is the NEC Vector computer.
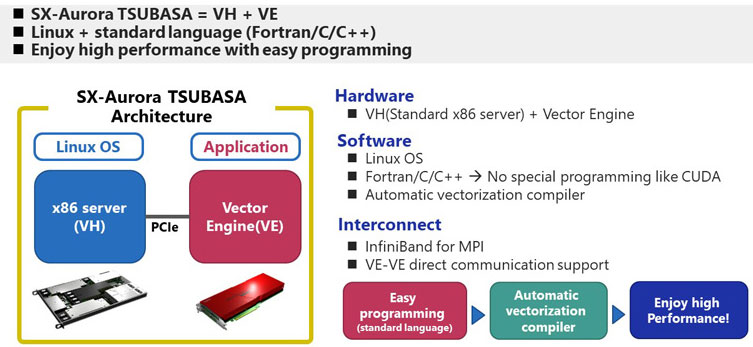 Architecture of NEC Vector Computer (SX-Aurora TSUBASA)
Architecture of NEC Vector Computer (SX-Aurora TSUBASA)In terms of architecture, SX-Aurora TSUBASA is similar to GPGPU. It is not standalone and requires x86 server as a host which is called Vector Host (VH). The vector processor is on the Vector Engine (VE) which is connected to VH by PCIe. Operating system is general Linux and you can use Fortran, C, C++ as programming language. It should be highlighted that there is automatic vectorization compiler which does the vectorization, parallelization and other optimization automatically to deliver high performance. This mean that you don't need special skills like CUDA and consume your time to do the complicated programming to gain performance. You can enjoy high performance with minimum effort.
This Vector Computer, SX-Aurora TSUBASA is suited for oil & gas applications and that is why it received Frost & Sullivan's Best Practices Awards in 2020.
 Frost & Sullivan Best Practices Award
Frost & Sullivan Best Practices AwardA detailed report from Frost & Sullivan says, "SX-Aurora TSUBASA can expedite new oil and gas reservoir discoveries by leveraging full-wave inversion and reverse time migration for seismic processing much faster than its peers". Let's see FWI(Full Wave Inversion) and RTM(Reverse Time migration) performance below.
The figure below shows FWI performance evaluation using an open source program named FWI mini-app.
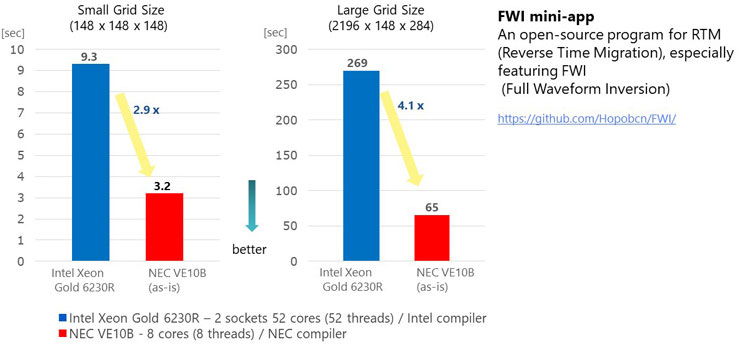 FWI (Full Waveform Inversion) Performance
FWI (Full Waveform Inversion) PerformanceThe evaluation compares Intel Xeon Gold 6230R and NEC Vector Engine. Here, we use exactly the same source code for Xeon and VE and compile it with Intel compiler and NEC compiler respectively. We can see that VE delivers more than 4 times higher performance than Xeon.
As for RTM, we used an open source code named Madagascar. Madagascar is a software package for multidimensional data processing and analysis. It comes with many sample programs related to oil & gas and here we used sample program named RTM2D to make a kernel program for easy comparison. Again, we used exactly the same source code (kernel made from RTM2D) and compiled it with Intel compiler and NEC compiler for Xeon and VE respectively.
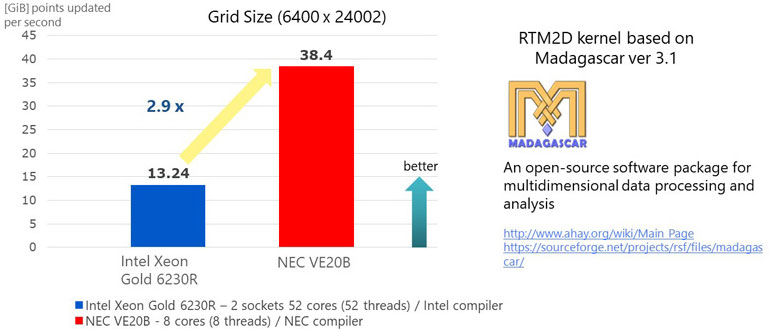 RTM (Reverse Time Migration) Performance
RTM (Reverse Time Migration) PerformanceIn this evaluation, we tested how many grid points are updated per second and found out that 1 node VE achieves almost 3 times better performance compared to 2 sockets of Intel Xeon 6230 processors.
From these evaluations, we actually confirmed that VE has advantage in seismic applications such as FWI and RTM. But what makes this advantage? The table below shows specification of the processors used in these evaluations. We can see that VE has less CPU performance less number of cores, lower frequency, but higher core performance and larger memory bandwidth.
| Processor | Cores | Freq. [GHz] | CPU perf. [Gflops] | Core perf. [Gflops] | Mem. Bandwidth [GB/s] | Mem. Bandwidth/core [GB/s] | |
| Intel Xeon Gold 6230R 2sockets | 26 x 2 | 2.1 | 1747 x2 | 67.2 | 140.7 x2 | 5.4 | |
| NEC Engine 20B | Vector Type | 8 | 1.6 | 2450 | 307 | 1530 | 191 |
It is known that FWI and RTM are very memory bandwidth hungry applications. We can understand that large memory bandwidth of VE contributed to feeding data to the high performance core and thus resulted in good performance. On the other hand, memory bandwidth was a bottleneck for Xeon and we can assume that data was not efficiently provided from memory to the processor to make use of many cores and high frequency.
We can expect similar results in other memory bandwidth hungry applications such as reservoir simulations. The use of AI/ML was not discussed in this technical description, either. But HPC and AI/ML is rapidly merging and complementing each other. These topics would be discussed in another technical description.
- The product and service names on this website are trademarks or registered trademarks of either NEC Corporation, NEC Group companies or other companies respectively.