Performance Benchmarking for Vector Version Spark SQL
Nov 16, 2021 Manami Abe, NEC Corporation and Sigapathy Nagarajan Raagul, NEC Corporation India Pvt. Ltd. Eduardo Gonzalez. Xpress AI GK
NEC have developed a Vector Engine (VE) for accelerated computing using vectorization, with the concept that the full application runs on the high performance Vector Engine and the operating system tasks are taken care of by the Vector Host (VH).
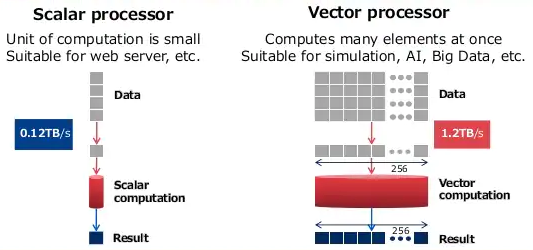
SX-Aurora TSUBASA is the latest model of NEC’s vector type supercomputer series. It consists of Vector Engine, PCI card, and x86 server. And the most distinctive features are large memory and high memory bandwidth. These features exert great power when you execute multiple processes in-memory. Actually, high performance in Vector version Spark SQL is achieved by utilizing the features.
The NEC SX-Aurora TSUBASA is a vector processor of the NEC SX architecture family. It is provided as a PCIe card, termed by NEC as a "Vector Engine" (VE). Eight VE cards can be inserted into a vector host (VH) which is typically a x86-64 server running the Linux operating system. It’s hardware consists of x86 Linux hosts with vector engines (VEs) connected via PCI express (PCIe) interconnect.
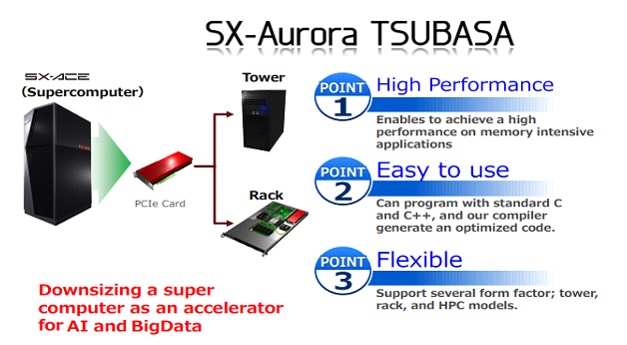
Introduction to Spark on SX-Aurora TSUBASA
Spark:
It is a distributed computing engine; it takes the concept of RDD (resilient distributed dataset) and allows you to write programs that are able to distribute computation to the data i.e. where the data is stored, it’s the goal of spark. Spark is capable of running 100 times faster than Hadoop MapReduce when running fully in-memory, and on the order of 10 times faster when using disk.
Built on top of Spark, MLlib is a scalable machine learning library consisting of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, and underlying optimization primitives.
Spark SQL:
Spark SQL is a Spark module for structured data processing, which enabled users of spark to write SQL queries to run computations. It provides a programming abstraction on top of Spark's native abstraction (the Resilient Distributed Dataset or RDD) called DataFrame and also acts as a distributed SQL query engine.
Spark SQL enables users of spark to write SQL queries to run computations. The advantage of this SQL queries is that usually they are little bit faster than running lambdas in Pyspark. As in pyspark, you have to stream data from the java site to python site and back. So by introducing Spark SQL in backend, they were able to take most of the immediate computations, as we don’t have to use the lambda, we can directly do that using Spark SQL syntax.
Spark for Vector Engine:
SX-Aurora TSUBASA supports Apache Spark and it can achieve much faster data processing speed and it is not required to change source codes or applications. SX-Aurora TSUBASA/Vector Engine also supports MLlib, which is a scalable machine learning library consisting of common learning algorithms and utilities. So we can easily and seamlessly perform data analytics process, from data preparation to Machine Learning.

It has three advantages:
- End-to-end data analytics,
- Improvement of the effectiveness and quality of data analysis,
- High performance.
Spark SQL includes new type of RDD which is called the “DataFrame” which also acts as a distributed SQL query engine and now this DataFrame API forms the basis of the Spark SQL backend. We do not have to use Spark SQL to use Aurora Spark plug-in, we can use DataFrames directly, likewise it is not required to use Scala to use backend as python can also be used as it works exactly the same. So taking regular DataFrame Spark SQL code which is created for CPU and by introducing a plug-in, it will automatically see if it could vectorise or accelerate that code. If it can then it will run that execution on VE and give us the results. It does in transparent manner i.e. there is no difference on running the code on CPU or VE.
When executing DataFrame operations or Spark SQL queries the Aurora4Spark plugin performs the following basic workflow:
- Compile executable for the necessary function using NCC
- Create a process handle loading the executable
- Create a context
- Allocate arguments
- Call the function by name
- Wait for the result
- Free memory
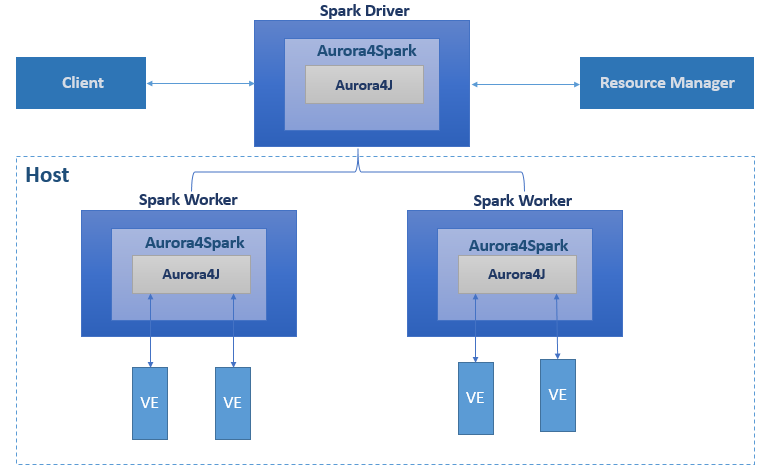 High-Level architecture of Spark for Vector Engine
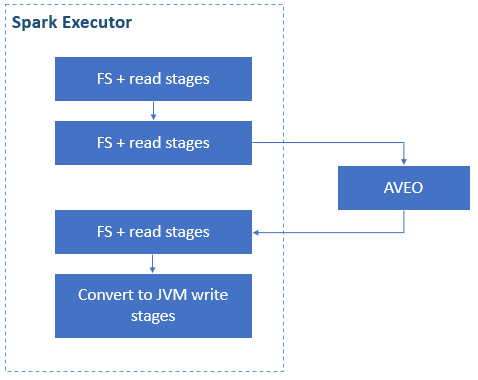
High-Level architecture of Spark for Vector EngineTo enable the Spark for Vector Engine plugin to accelerate DataFrame operations on the VE, we created the Aurora4j library which contains bindings to interact with the NEC vector engine over the Alternative Vector Engine Offloading (AVEO) library for low latency computation offloading. The main function is to ensure data gets sent back and forth to the vector engine from Java in an efficient manner with minimal data copying.
Benefits of Spark SQL on Vector Engine
VE has lots of memory with high bandwidth, so Spark can run Map Reduce on Memory. Also when there are many multiple processes, VE can operate entire process inside the memory. Using Spark SQL on Aurora Vector Engine can be beneficial in many ways, as shown below:
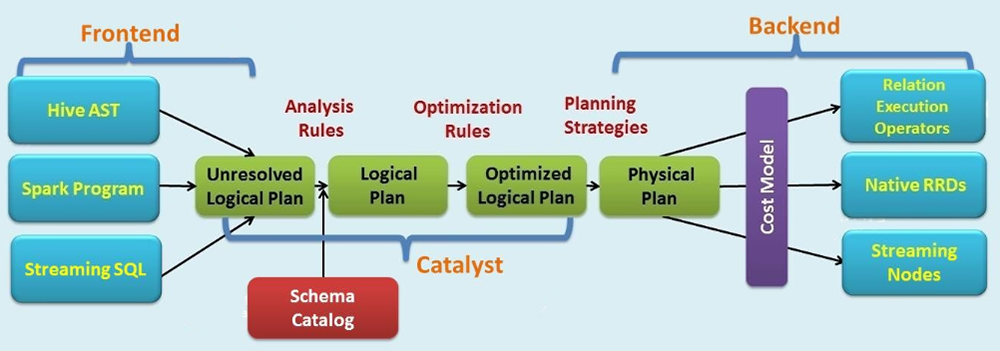
Catalyst Plug-in:
To speed up the SQL and DataFrame process of Spark, we implement Aurora acceleration plugin for Catalyst which is used for the query optimization for Spark SQL. Mainly it performs 3 functions:
- Analysis: Resolve unsolved attribute using Catalyst rules
- Logical Optimization: Apply standard rules
- Physical Planning: Generate one or more physical plans and choose the best physical plan using the cost model
Shuffle Function:
By implementing the Shuffle function of VE version of Spark using AVEO, data transfer between Spark nodes can be accelerated. When performing sort, group and join operations in Spark, data movement occurs between partitions. The process of creating a new DataFrame from one DataFrame between stages in this way is called shuffle.

Shuffle first writes data to a local disk and then transfers the data over the network to other CPU or VE partitions. Shuffle involves disk I / O, data serialization, and network I / O, which is costly in terms of CPU, RAM, disk, network, and PCI-e bus traffic.
Apache Arrow:
By implementing the Apache Arrow for Aurora, we can accelerate the performance of memory access. It can access the data with non-copy and it means overhead of data serialization and de-serialization will be removed. AVEO is also used for the performance boost.
Advantages of Apache Arrow:
- Column Store: Data is stored based on columnar format
- Searching the entire column data is fast
- Fast access to column data (such as a specific year or month)
- Fast execution of value aggregation for specific column data (average, total, etc.)
- Zero Copy: By using Arrow memory format, all of the system can use the format seamlessly
- Eliminate overhead when using data between systems
- The cost of serialization and de-serialization can be reduced dramatically
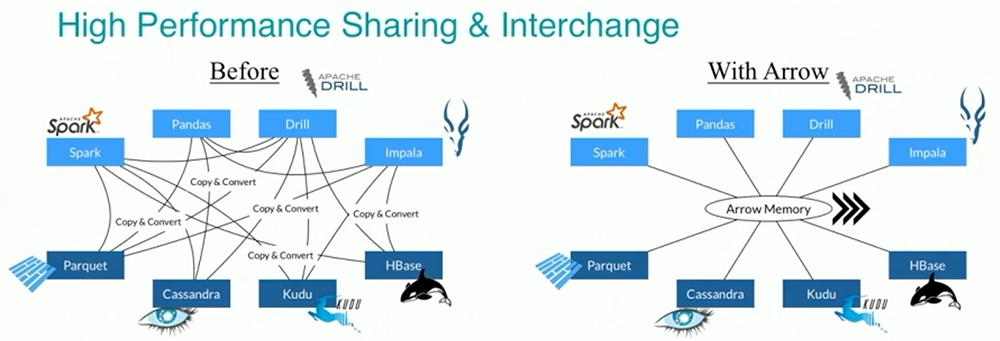
Referred from Dremio Website: https://www.dremio.com/webinars/vectorized-query-processing-apache-arrow/
Support Scheduling Functions:
Implementing the functions to recognize VE as a first-class resource together with CPU and system memory. If VE resources are required to speed up Spark jobs, this implementation can recognize the server containing VE resources and submit a workload based on VE.
Different Implementation of Spark SQL Backend for Vector Engine
Apache Spark enables users to process large amounts of data that would be too large to fit in a single machine by distributing the job across a cluster of machines. In order to parallelize the job efficiently, Spark requires a resource manager to help it schedule processes that are near to the data. In this project, we are using YARN as the resource manager.
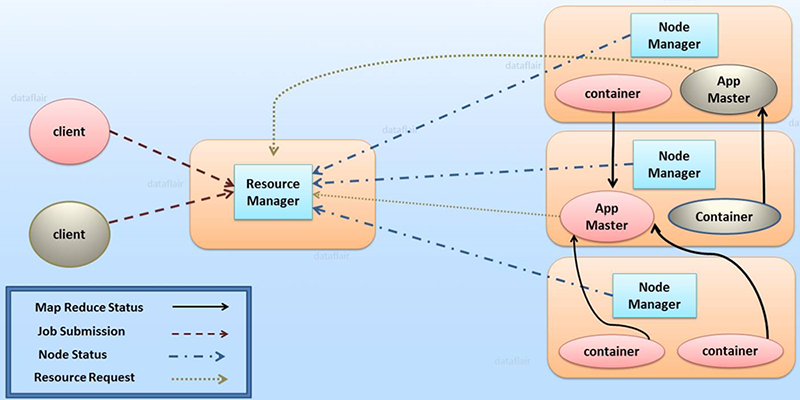 Yarn Architecture
Yarn ArchitectureAside from YARN, we can also use Kubernetes as it has a large advantage over YARN in that it is better suited to running not only batch jobs like Spark, but also interactive services, which enables better resource usage for a cluster of machines. In this project we are also implementing a Kubernetes Device Plugin for the VE so that we can also use Kubernetes as a resource manager.
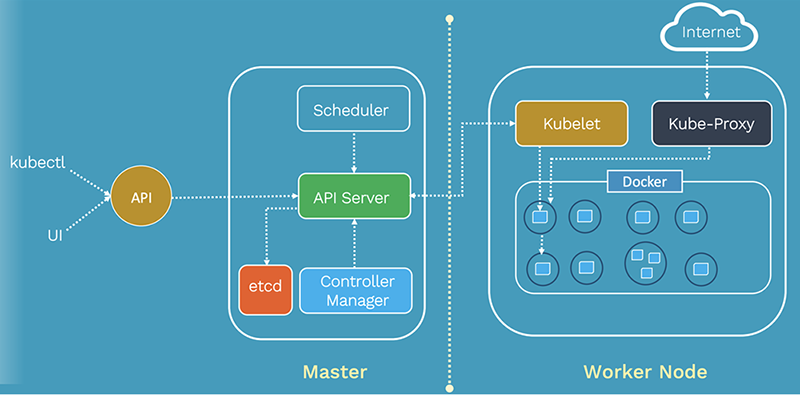 Kubernetes Architecture
Kubernetes ArchitectureComparison using TPC Standard Benchmarks
Benchmark 1: TPC-H Benchmark
The TPC-H benchmark is a decision support benchmark and consists of a suite of business oriented ad-hoc queries & concurrent data modifications. This benchmark comprises of 22 analytics queries and they have ideal workloads to evaluate the analytics focused Apache Spark framework.
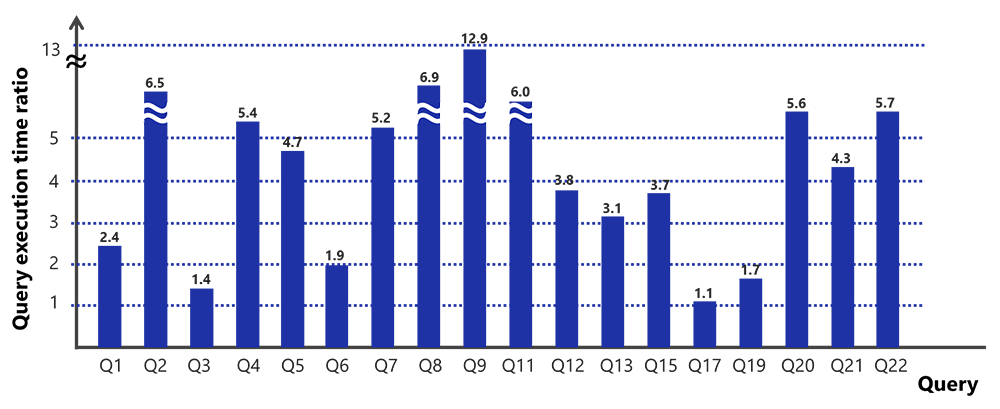
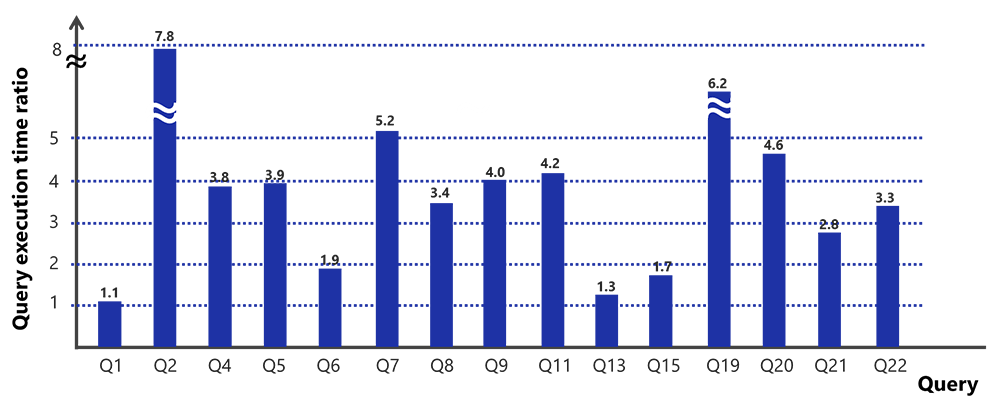
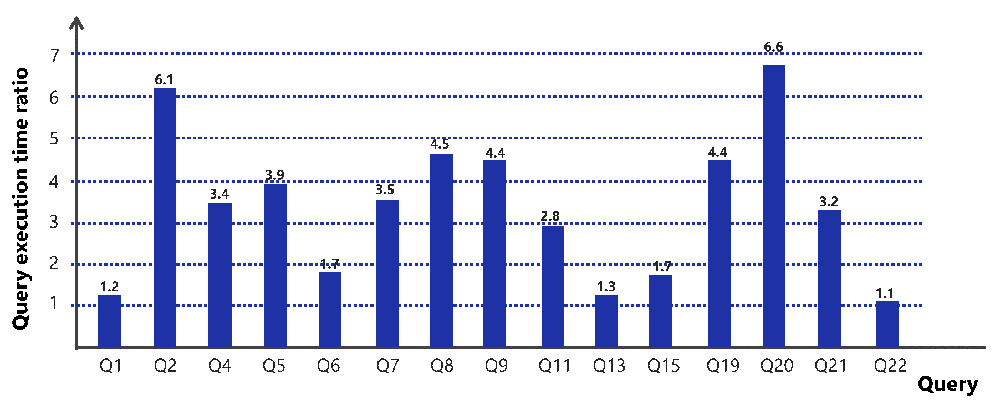
The below bar charts shows the GPU / VE query execution time ratio for each individual query of TPC-H benchmark. Various sizes of data ranging from 1GB to 20GB was evaluated in the benchmark and results shows that SX-Aurora TSUBASA / Vector Engine performs better as compared to GPU.
SX-Aurora TSUBASA / Vector Engine shows improved performance for 15 of the 22 queries of TPC-H benchmark. For the 7 remaining queries, the performance comparison will be shown in the next framework release. (Note: Of the 7 remaining queries, 3 shows improved performance at scale 1)
GPU / VE ratio at scale 1:
GPU / VE ratio at scale 10:
GPU / VE ratio at scale 20:
Instructions for running Benchmarks on VE, GPU & CPU
The benchmark code can be found here:
https://github.com/XpressAI/SparkCyclone/tree/main/tests/python
Specifically, you would firstly run the generate_data.py to generate the benchmark dataset, then run_benchmark.py. The report will be in csv form.
As for this report, we are using YARN as the cluster manager.
Instructions for running on VE:
Step 1: Clone the spark for Vector Engine repository:
git clonehttps://github.com/XpressAI/SparkCyclone
Step 2: Generate the benchmark dataset:
/opt/spark/bin/spark-submit --master yarn generate_data.py data/1K -r 100000000
Where -r is the row flag to set the number of rows. You may also specify the number of partitions using -p and filetype using -ft (currently supporting csv, parquet, and json).
Step 3: Run the bash script:
#!/bin/bash /opt/spark/bin/spark-submit --master yarn \
--deploy-mode cluster \
--py-files dep.zip \
--conf spark.com.nec.spark.ncc.path=/opt/nec/ve/bin/ncc \
--jars /opt/aurora4spark/aurora4SparkSQL-plugin.jar \
--conf spark.plugins=com.nec.spark.AuroraSqlPlugin \
--conf SparkSQL.columnVector.offheap.enabled=true \
run_benchmark.py data/100M_R100000000_P100_csv \
-x 4g -d 4g \
-o output/test_ve_100M_clearcache \
-t column \
-l "sum,avg,(x+y),avg(x+y),sum(x+y)" \
-n 5 \
--clearcache
/opt/hadoop/bin/hadoop dfs -rm -r -f temp
Where -x is the executor flag that sets executor memory size, -d is the driver flag that sets driver memory, -o is the output file flag where you can specify output file name (CSV), -t is the type flag, column operations being the first to be supported.
Step 4: The benchmark results can be viewed in the generated csv
Instructions for running on CPU:
Step 1,2 & 4 to run on CPU and GPU are the same as the VE
Step 3: Run the bash script:
#!/bin/bash
/opt/spark/bin/spark-submit --master yarn \
--deploy-mode cluster \
--py-files dep.zip \
-x 4g -d 4g \
-o output/testing \
-t column \
-l "sum,avg,(x+y),avg(x+y),sum(x+y)" \
-n 5 \
--clearcache
/opt/hadoop/bin/hadoop dfs -rm -r -f temp
Instructions for running on GPU:
The instructions for running on NVIDIA GPUs are similar to running on the VE / CPU.
Note that CUDA 10.1 should be installed and available on the system
Step 3: Run the bash script:
#!/bin/bash
/opt/spark/bin/spark-submit --master yarn \
--deploy-mode cluster \
--py-files dep.zip \
--jars 'rapids.jar,cudf.jar' \
--conf spark.plugins=com.nvidia.SparkSQLPlugin \
--conf spark.rapids.sql.incompatibleOps.enabled=true \
--conf spark.rapids.sql.explain=ALL \
--conf SparkSQL.cache.serializer=com.nvidia.spark.rapids.shims.spark311.ParquetCachedBatchSerializer\
--conf spark.rapids.sql.csv.read.float.enabled=true \
--conf spark.rapids.sql.csv.read.integer.enabled=true \
--conf spark.rapids.sql.variableFloatAgg.enabled=true \
run_benchmark.py data/100M_R100000000_P100_csv \
-x 4g -d 4g \
-o output/test_gpu_100M_clearcache \
-t column \
-l "sum,avg,(x+y),avg(x+y),sum(x+y)" \
-n 5 \
--clearcache
/opt/hadoop/bin/hadoop dfs -rm -r -f temp
Installation Procedure for Spark for Vector Engine:
Repository Layout on GitHub:
Layout for the organisation of code, it contains folders for both documentation and code. There are lot of folders where we can compile the plug-in for ourselves:
- Aveo4j: It is used to run code on VE, we implement it using “veo” library
- docs: It contains all the documentation of the project.
- examples: It has little scripts which we can run & see results.
- src: It contains most of the stuff related to the project.
Installation Procedure for VE on YARN:
- Download Hadoop 3.3 (or later) and spark 3.1.1 (or later) built for Hadoop 3.2.
- Create the Hadoop user
- Set the Hadoop user to be able to ssh to localhost without password
- Press enter to accept all defaults
- Ensure Java is installed
- Create profile.d script to set hadoop variables for all users.
- Login again and verify variable set.
- Extract Hadoop and spark downloads into /opt/Hadoop and /opt/spark
- Add ve-spark-shell.sh
- Change ownership of /opt/hadoop/ /opt/spark to Hadoop user
- Install pdsh
- Set Hadoop configuration
- Set up HDFS and Yarn
| Abbreviations: | |
| VE | Vector Engine |
| VH | Vector Host |
| PCIe | PCI express |
| GPU | Graphical Processing Unit |
| CPU | Computer Processing Unit |
| RDD | Resilient Distributed Dataset |
| MLlib | Machine Learning Library |
| AVEO | Alternative Vector Engine Offloading |