SCA: A Library to Accelerate Stencil Codes on Vector Engine
Nov 1, 2020, Arihiro YOSHIDA (Numerical Library Engineer), Ryusei OGATA (Numerical Library Manager), AI Platform Division, NEC Corporation
Stencil codes are typical costly computing patterns appearing in a wide variety of domains.
To accelerate execution of stencil codes, we provide a library named Stencil Code Accelerator, SCA.
SCA realizes this acceleration by utilizing the computation power of Vector Engine.
In this article, first we explain "stencil code", and then we introduce SCA with its performance.
1. Stencil Code Overview
- What is “stencil code”?
- A computing pattern that frequently appears in scientific simulations, image processing, signal processing, deep learning, etc.
- Updates each Element in a multidimensional array by referring to the neighbour elements
 Requires significant performance of both computation and memory access
Requires significant performance of both computation and memory accessBefore we introduce the library SCA, we need to explain, what is a "stencil code".
It is a computing pattern that frequently appears in scientific simulations, image processing, signal processing, deep learning, and so on. It updates each element in a multidimensional array by referring to the neighbor elements. So, it requires significant performance of both computation and memory access.
Typical Example
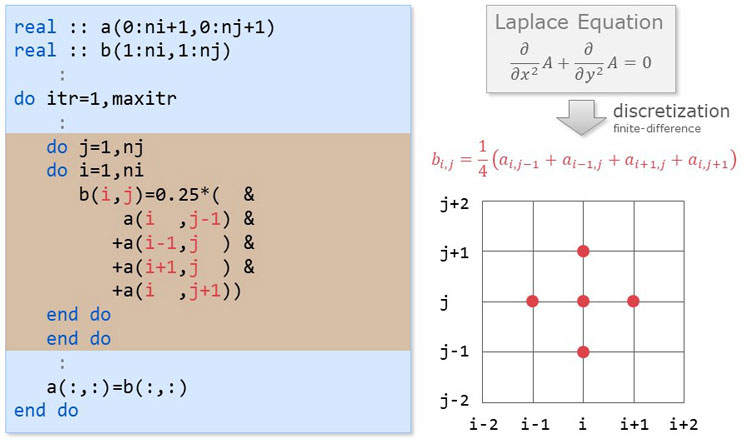
This is an example of a stencil code. The left is a source code in Fortran, where the lines of the stencil code are highlighted. It is implemented based on the equation on the right side (colored red), which is derived by discretizing a Laplace equation using the finite-difference method. The value of b(i,j) is updated by referring to the values of 4 neighbor grid points a(i,j-1), a(i-1,j), a(i+1,j), and a(i,j+1).
Applications
Domains where Stencil Codes appear
- Scientific Simulations
- Fluid Dynamics
- Thermal Analysis
- Electromagnetic Field Analysis
- Climate / Weather
- Seismic Imaging
- Etc.
- Signal Processing
- Audio, sonar
- Rader, Radio Telescopes
- Etc.
- Image/Volume Data Processing
- Retouch
- Data Compression
- Recognition
- Medical Diagnosis (Biopsy, CT, MRI, …)
- Etc.
- Machine Learning
- Deep Learning (Convolutional Neural Networks)
This shows the domains where stencil codes appear. As you can see in this list, stencil codes appear in a wide variety of domains.
Stencil Code Accelerator
- Library Features
- Highly optimized for Vector Engine
- Supports up to 4-dimensional stencils with any shapes
- APIs for C/C++ and Fortran
- API Usage Flow
- Initialization:
- Create a “stencil description”
- Set stencil element attributes and an output array to the “stencil description”
- Create a “stencil code” using the “stencil description”
- Destroy the “stencil description”
- Computation:
- Execute the “stencil code”
- Finalization:
- Destroy the “stencil code”
To reduce the execution time of the programs that have stencil codes, we provide a library named Stencil Code Accelerator, SCA. It can highly accelerate execution of stencil codes by utilizing the computation power of the Vector Engine. It supports up to 4-dimensional stencils with any shape. You can use it in C, C++ and Fortran programs.
To use SCA in your program, you need to follow 3 steps: initialization, computation, and finalization. In the initialization step, a "stencil code" needs to be created using a "stencil description". Here, a "stencil description" is the information about stencil element attributes and an output array, and a "stencil code" is an executable binary generated on memory.
In the computation step, the "stencil code" is executed. Usually, it is done repeatedly until the time step reaches the end or convergence conditions are met.
In the finalization step, the "stencil code" needs to be destroyed.
Example Code using SCA
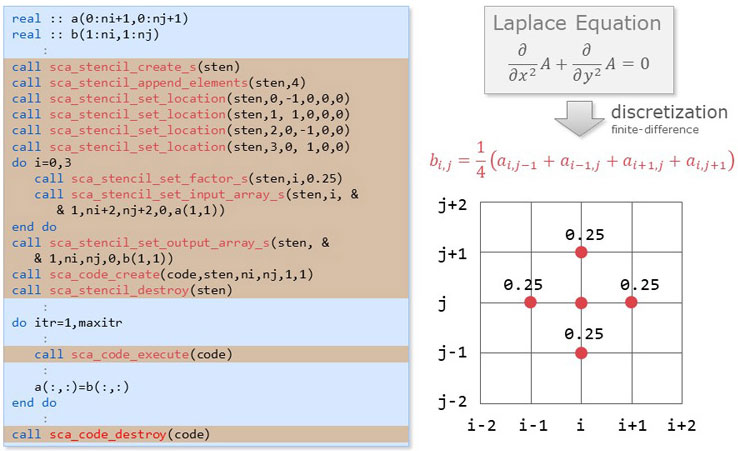
This is an example of a stencil code using SCA. The left is a source code in Fortran, where the lines of SCA routine calls are highlighted. The first highlighted part corresponds to the initialization step. A highly optimized executable binary of the stencil code is generated on memory. The second highlighted part corresponds to the computation step. The binary of the stencil code is executed here. The last highlighted part corresponds to the finalization step.
Stencil Code Optimizing Software for Other Platforms
Most are frameworks with domain specific languages, not libraries
- YASK (https://github.com/intel/yask/)
- C++ framework to generate optimized stencil code kernels
- Uses a C++-like domain specific language, which is translated in C++
- Targeted at x86 processor including Xeon Phi
- Physis (https://github.com/naoyam/physis/)
- C/C++/CUDA framework to generate optimized stencil code kernels
- Uses a C-like domain specific language, which is translated in C/C++/CUDA
- Mainly targeted at NVIDIA GPUs
- And more…
- Patus (https://github.com/matthias-christen/patus/)
- LibGeoDecomp (https://libgeodecomp.org/)
- We could not bring out their good performance so far
We investigated stencil code optimizing software for other platforms. We found that most are frameworks with domain specific languages, not libraries. For benchmarking, we took two frameworks. The first is YASK, which is a C++ framework using a C++-like domain specific language. It is developed by Intel, and targeted at x86 processors including Xeon Phi. The second is Physis, C/C++/CUDA framework using a C-like domain specific language. It is mainly targeted at NVIDIA GPUs.
Benchmark Conditions
- Stencil Shape
- XYZ-axial, size 1-6
- The most commonly used in scientific simulations
- Particularly for seismic imaging, large ones are often used
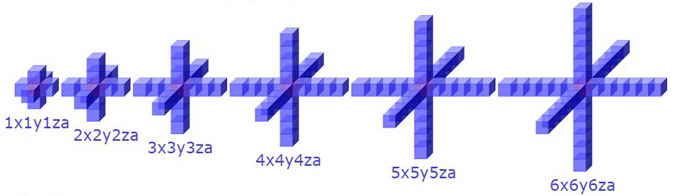
- Data Size
- Computing domain: 1024x1024x512
- Determined so that Tesla V100 16GB can retain it
We did benchmarking under these conditions. We chose stencil shapes that are most commonly used in scientific simulations. Particularly for seismic imaging, large ones are often used. The computing domain size is 1024x1024x512.
Performance Comparison
SCA on Vector Engine shows the highest performance
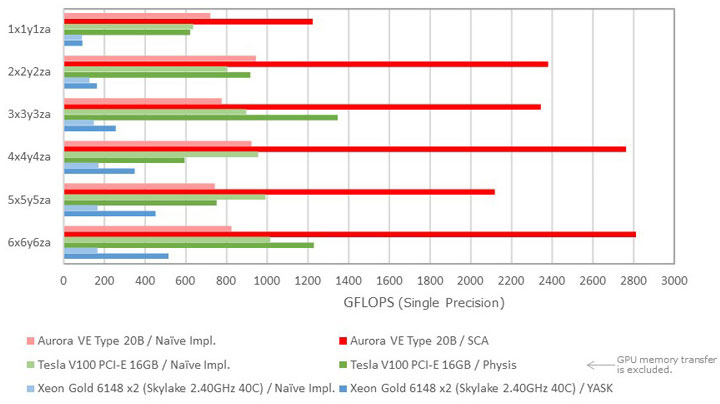
This chart shows the benchmarking results. The pink and red bars are a naïve implementation and SCA executed on Vector Engine Type 20B, respectively. The light green and green bars are a naïve implementation and Physis executed on Tesla V100, respectively. The light blue and blue are a naïve implementation and YASK executed on Xeon Skylake 40 cores, respectively. Looking at the red bars, SCA shows the highest performance. In particular, the performance reaches 2.8 TFLOPS for the stencil shape "6x6y6za".
Conclusion
- Stencil codes appear in a wide variety of domains, and create large computing costs
- We provide SCA, which is a library to highly accelerate stencil codes on Vector Engine
- SCA achieves 2.8 TFLOPS for stencil shapes commonly used in scientific simulations
- The performance is superior to that of stencil code optimizing software for scalar processors and GPGPUs
Stencil codes appear in a wide variety of domains, and create large computing costs. To reduce the execution time of the programs that have stencil codes, we provide SCA, which is a library to highly accelerate execution of stencil codes on the Vector Engine. SCA achieves 2.8 TFLOPS for stencil shapes commonly used in scientific simulations. The performance is superior to that of stencil code optimizing software for scalar processors and GPGPUs.
The online manuals of SCA are available at the following URLs:
- https://www.hpc.nec/documents/sdk/SDK_NLC/UsersGuide/sca/c/en/index.html for C and C++
- https://www.hpc.nec/documents/sdk/SDK_NLC/UsersGuide/sca/f/en/index.html for Fortran.
- Intel and Xeon are trademarks of Intel Corporation in the U.S. and/or other countries.
- NVIDIA and Tesla are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries.
- Linux is a trademark or a registered trademark of Linus Torvalds in the U.S. and other countries.
- Proper nouns such as product names are registered trademarks or trademarks of individual manufacturers.