Library
Applications for SX-Aurora TSUBASA (samples)
Library
MUMPS (MUltifrontal Massively Parallel sparse direct Solver)
Application Overview
The scientific library MUMPS is a solver for large linear systems and a key component in many areas of HPC. It solves large sparse systems of linear equations A x = b by using Gaussian elimination.
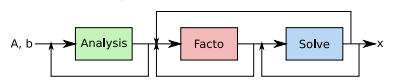
There are three steps for solving these systems: analysis, factorization and solving.
The most important part and a key step which consumes the most computation time and memory resources is the factorization which therefore has the most potential for optimisation and tuning.
MUMPS is a key component in many numerical simulation codes worldwide. The package is integrated in free open source, commercial and internal software used for digital twin and product development worldwide.
The outstanding advantage of MUMPS is its robust and effective way to solve equations on high performance systems. It runs on distributed as well as shared memory systems and is a result of more than 20 years of research and development.
MUMPS Technologies has been founded in 2019 by Jean-Yves L’Excellent, Chiari Puglisi and Patrick Amestoy. They now develop, support and provide services on MUMPS.
The team behind include some of the major experts in finding solutions of sparse linear systems of equations A x = b by using direct methods.
Besides the development and updates, MUMPS Technologies are active in research and high-level international publications. Their research projects are in the field of applied mathematics and computer science.

The development team pursues R&D and continues transferring MUMPS into an ‘up-to-date’ tool to face the evolution of the size and the difficulty of the problems.
Those remain challenging:
- Minimization of power consumption
- Further reduction of the complexity of the approaches
- Computation of precision-controlled solutions
- Provision of new algorithms that meet the need for massive data processing
A mayor step will be taking into account the profound changes in hardware architectures for CPUs as well as accelerators.
For that reason NEC Corporation and MUMPS Technologies joined forces to provide a full operational version of MUMPS supported natively on the NEC SX-Aurora Vector Architecture in less than one year. This was done by directive insertions and code optimizations which allow for maintaining one source code for vector and scalar processors. The only exception was the offloading of the METIS call in the analysis step to the CPU, which is fully transparent to the user though. The first working step has lead to an easy first official version of MUMPS that supports NEC SX-Aurora TSUBASA.
More improvements will be implemented regularly in upcoming versions.
Gold member that found MUMPS and participate widely in the development of the product evolution:

Usage
The usage of MUMPS and sparse linear algebra is for solving many physical problems in:
- Geophysics
- Structural Mechanics
- Fluid Dynamics
- Electromagnetics
- Acoustics
- …
MUMPS provides a better robustness in strong problems from energy, oil and gas, automotive, aeronautic and many other fields.
In these fields the solution of sparse linear systems of equations is one of the most critical and costly part (in terms of computing time and memory usage) of a numerical simulation.
The time spent in the solution of the linear systems typically reaches 80% of the total time for the simulation. Moreover, the numerical simulation often leads to linear systems that are large and, sometimes, ill-conditioned. It is then fundamental to rely on sparse solvers capable of solving large systems while achieving high performance and maintaining numerical stability.
| Model | Launched | Cores | Frequency | Performance | Memory | Bandwith |
| Aurora Type 20B | 2018 | 8 | 1.6 GHz | 2.45 TFLOPS | 48 GB | 1,530 GB/s |
| 2 AMD 7542 | 2019 | 32 | 2.9 GHz | 2.9 TFLOPS | 264 GB | 279 GB/s |
| 2 INTEL ICELAKE 6346 | 2021 | 16 | 3.1 GHz | 3.1 TFLOPS | 256 GB | 298 GB/s |
Acceleration:
Real cases will be compared on the following architectures:
The performance of Aurora 20B has been compared against a full bi processor server based on recent Intel and AMD processors dedicated to HPC.
This comparison is done on four cases which are representative of the one who can run on one VE. These come from realistic cases which are usually solved by the sparse linear algebra solvers. In the following description N is the dimension of the square Matrix and NNZ the number of non-zero values represented in the matrix.
Atmosdl (CFD case)
 |
CurlCurl_4 (Model reduction case)
 |
Serana (Structural mechanics case)
 |
dielFilterV3real (Electromagnetism case)
 |
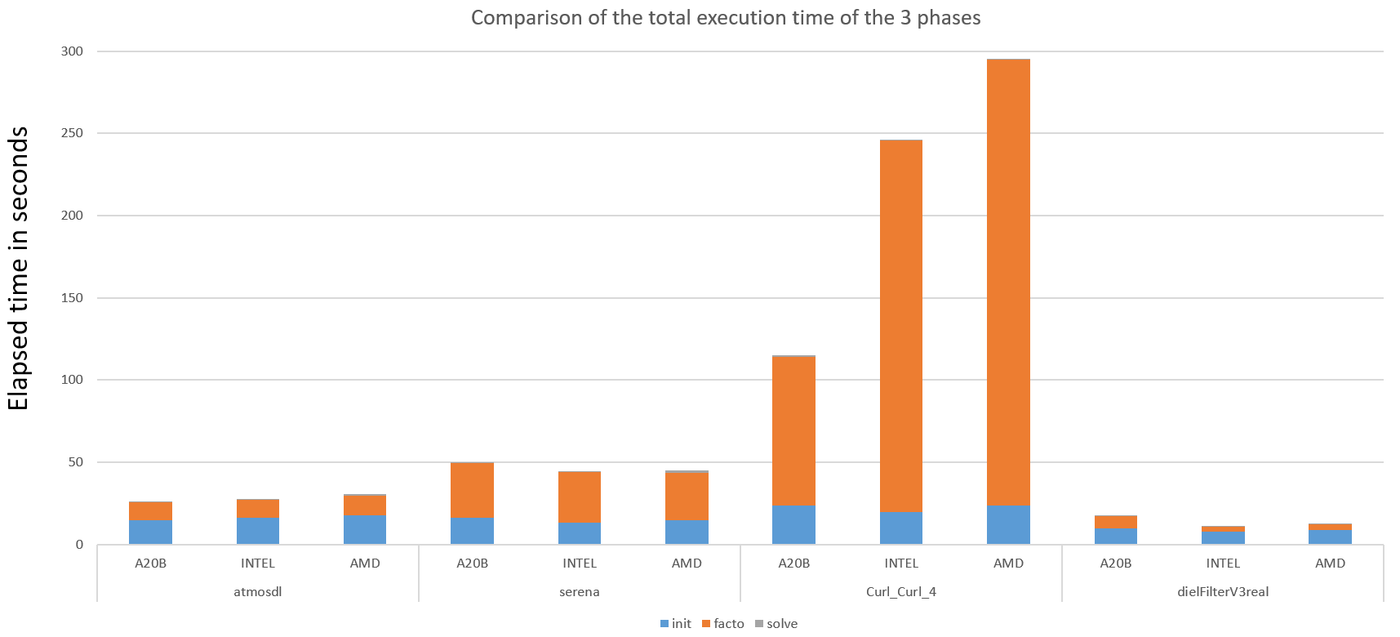
As shown in the figure below the results for the four cases are described for the three architectures. The computations are done with seven Right Hand Side vectors in order to imply all the subroutines of the library.
The results show that one Aurora 20B card has the same performance or better than a server with two HPC processors from AMD or two from Intel.
Since time consumed by the initialization phase on blue remain the same on all the architecture is due to the fact that this step is offloaded to the CPU. This means that there is no penalty for offloading to the CPU.
The solve phase in grey is also nearly the same on all architecture but it hasn’t been worked on since this step is non-significant on the global time of a full resolution.
Finally in orange is the factorization step, which show that with one vector card you could have the same or in some cases better efficiency as two modern HPC CPUs.
Developer: MUMPS Technology