NLCPy: NumPy-like Python Library Accelerated with Vector Engine
Nov 1, 2020, Shota KURIHARA (Numerical Library Engineer), Ryusei OGATA (Numerical Library Manager), AI Platform Division, NEC Corporation
NumPy is a very important library in AI and scientific computing fields. NEC is developing NLCPy in order to accelerate NumPy scripts on the Vector Engine of SX-Aurora TSUBASA, and has published the preview release version of NLCPy back in August 2020.
In this article, we describe an overview of NLCPy and its performance. In addition, we introduce our experimental implementation, "Just-In-Time compilation" functionality, which can dynamically optimizes NLCPy scripts during the execution. The functionality will be able to boost the performance of NLCPy scripts.
In short words, NLCPy is a NumPy-like library accelerated with SX-Aurora TSUBASA. Python programmers can use the library from an x86 server of SX-Aurora TSUBASA. NLCPy enables NumPy scripts to accelerate heavy computation using Vector Engine of SX-Aurora TSUBASA, and provides a subset of NumPy's API. It is published on GitHub and PyPI as an open-source library, and the source code is licensed under the BSD 3-clause license. Installation is easy, only execute the command "pip install nlcpy".
Usage
Just by replacing the module name, Python scripts using NumPy can utilize VE computing power
- Example of Python Script
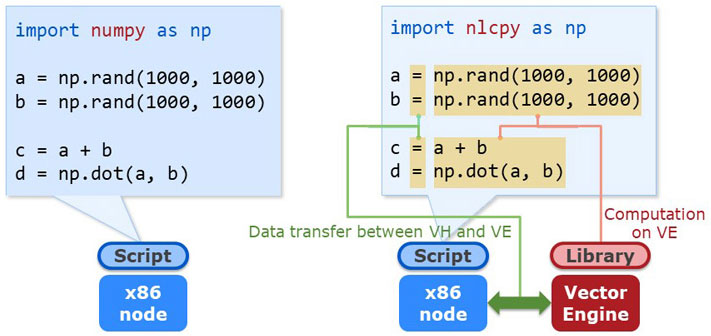
The figure shows an execution image of NumPy and NLCPy. The example to the left is a NumPy script working on an x86 server. On the other hand, the example to the right is a NLCPy script working on SX-Aurora TSUBASA. NumPy programmers can use NLCPy so easy. Just by replacing the module name "numpy" with "nlcpy", Python scripts using Numpy can utilize VE computing power. When using NLCPy, the computation will be performed on VE, and the data transfer between VH and VE will be done automatically.
Provided Functions
- Comparison with NumPy
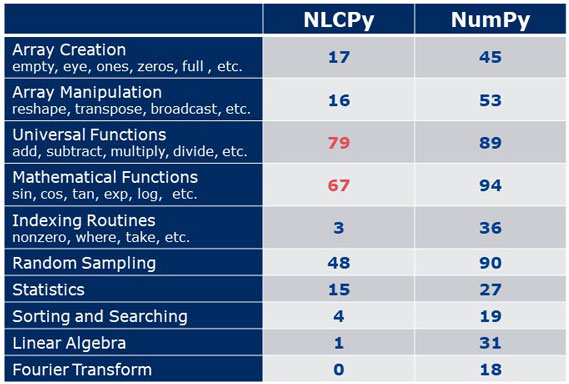
This table shows comparison of functionalities supported by NLCPy and NumPy. Here, the numbers in the table mean the number of supported functions. In the preview release, we focused on universal functions and mathematical functions, which are NumPy's typical functions. However, we think this coverage is not sufficient. For pursuing more usability, we will continue to expand the coverage.
Performance for Typical Operations
NLCPy boosts many operations compared with NumPy (CPU)
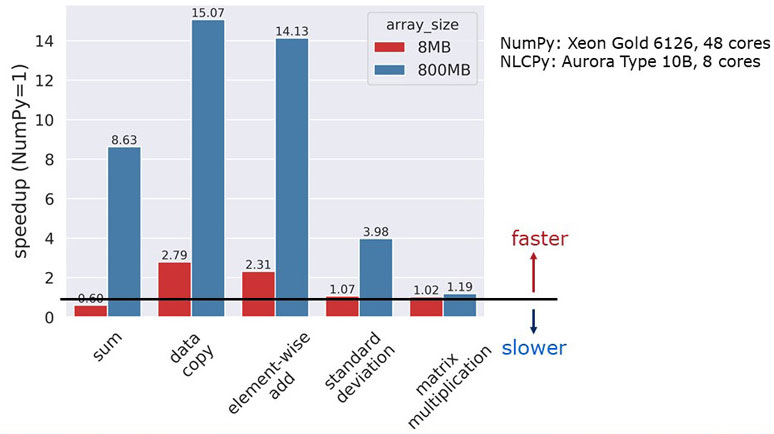
The next figure indicates NLCPy speed up ratio compared with NumPy. The measured operations are sum of array elements, data copy, element-wise add, standard deviation, and matrix multiplication. The vertical axis indicates how many times faster NLCPy is compared to NumPy. A bar higher than the black line means NLCPy is faster than NumPy. As you can see in this figure, NLCPy boosts performance of many operations compared with NumPy.
A Performance Issue of the Current NLCPy
- Not optimized for element-wise operations with more than two terms
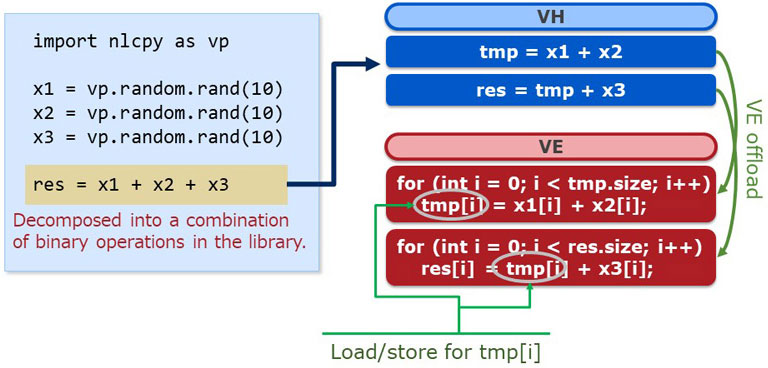
- This causes extra loops and extra memory access
⇒ Decreases NLCPy’s performance
Now, we'll introduce our experimental implementation: "Just-In-Time (JIT) compilation" functionality. The reason why we developed this functionality is that the current NLCPy has a performance issue. The issue is that it is not optimized for element-wise operations with more than two terms. The figure indicates an example case. The highlighted part is the three-term element-wise add. In NLCPy, this expression is decomposed into a combination of binary operations. The figure on the right side is the image of this decomposition. This two subexpressions are sequentially offloaded into the VE. As a result of that, extra loops and extra memory access occur.
In this case, extra loops indicate two "for" loops and extra memory access indicates load/store for the "tmp" array. This decreases NLCPy's performance.
In the first place, why does it need to be decomposed into a combination of binary operations? The reason is that there are an infinite number of combinations of various types of operators. Therefore, it is almost impossible to prepare pre-compiled binaries corresponding to respective combinations. To solve this problem, we experimentally implemented the "Just-In-Time (JIT) compilation" functionality.
JIT Compilation Process
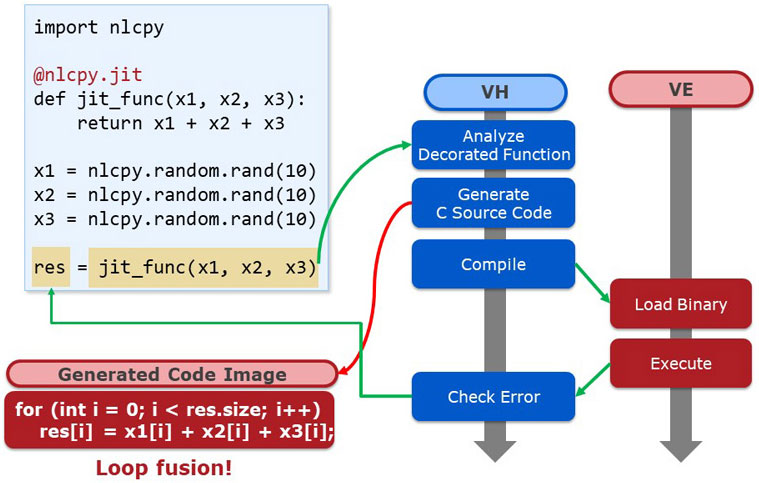
The usage of JIT compilation is simple. The upper left part of the next figure shows an example. Just by adding "nlcpy.jit" decorator, NLCPy dynamically generates a single VE binary with a fused loop. Please note that it is necessary to cut out computations to be compiled dynamically as a function. When called the function that is decorated with nlcpy.jit is analyzed on the VH. Next, the C source code is generated according to an analysis result. The lower left side is the generated code image. The element-wise operation with three array terms x1, x2 and x3 are calculated in a single loop. Then, this code is compiled with a VE compiler, the binary is loaded on a VE and is executed. Lastly, error check is executed on the VH and the calculation result is returned to the left term. That's the overview of the JIT compilation process.
Performance with JIT Compilation
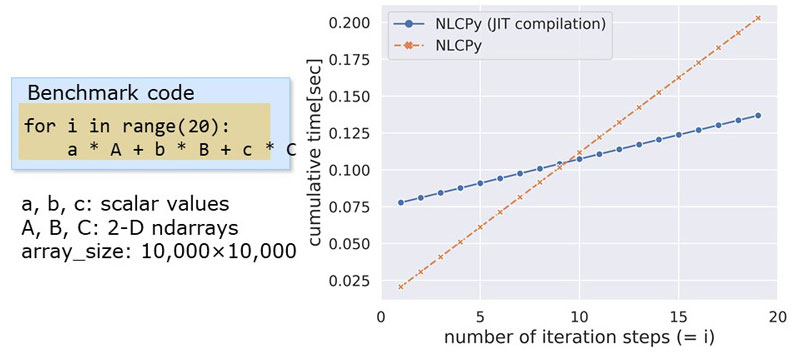
The next figure indicates the performance comparison between NLCPy with and without JIT compilation. We used the benchmark code on the middle left in the figure to evaluate the performance. The graph shows the cumulative time for up to 20 iteration steps. As you can see, the execution time of NLCPy with JIT compilation is larger until 10 steps. This is because of the initial overhead brought by compilation and binary load. However, as the number of iteration steps increases, the cumulative time of NLCPy with JIT compilation becomes smaller than that of NLCPy without it.
Performance Benchmarking
- NLCPy shows higher performance than NumPy (CPU)
- When array size is 1024Mbytes, NLCPy shows slightly higher performance than CuPy (GPU)

We evaluated the library performance with "2-D Heat Simulation", which simulates the thermal change on a 2-D surface using the finite-difference method. The surface update was iterated for 1,000 time steps. The target libraries are NumPy, NLCPy, and CuPy. CuPy is a NumPy-like library for GPU. NumPy was executed on Xeon Gold 6126 x2 (Skylake, 2.60GHz, 48 cores), NLCPy was executed on VE Type20B, and CuPy was executed on Tesla V100. The data type was single precision. We simulated it with 4 data sizes, increased by 4 times from 16MBytes to 1024MBytes. The figure shows the benchmark results with 2-D heat simulation. The vertical axis shows calculation array size, and the horizontal axis shows GFLOPS. The blue bars indicate NumPy, the pink bars indicate normal NLCPy, and the red bars indicate NLCPy with JIT compilation. The light green bars indicate normal CuPy, and the deep green bars indicate CuPy with fusion. CuPy's Fusion is equivalent to NLCPy's jit compilation, and it fuses multiple GPU kernels into a single GPU kernel at runtime. As you can see, NLCPy shows higher performance than NumPy for all array sizes. Additionally, when the array size is 1024Mbytes, NLCPy with JIT compilation shows slightly higher performance than CuPy with Fusion.
We'll plan to release an updated NLCPy's version in April 2021. Specifically, it will then support FFT and Linear algebra functions. In addition, it will have more statistic functions and array creation/manipulation functions. The JIT compilation will be supported in a future release. At the earliest, it will be supported next April.
Our mailing list, GitHub URL, and documentation URL are as follows:
- Mail: dev-nlcpy@sxarr.jp.nec.com
- GitHub: https://github.com/SX-Aurora/nlcpy
- Documentation: https://www.hpc.nec/documents/nlcpy/en/
Your feedback is welcome! Please do not hesitate to contact us.
- Intel and Xeon are trademarks of Intel Corporation in the U.S. and/or other countries.
- NVIDIA and Tesla are trademarks and/or registered trademarks of NVIDIA Corporation in the U.S. and other countries.
- Linux is a trademark or a registered trademark of Linus Torvalds in the U.S. and other countries.
- Proper nouns such as product names are registered trademarks or trademarks of individual manufacturers.