Machine Learning
Machine Learning Acceleration by the NEC Frovedis Library
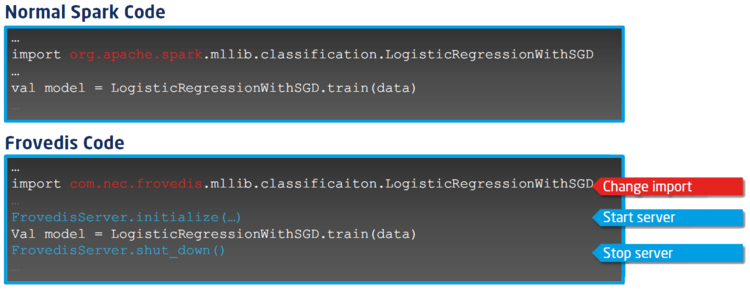
Frovedis (FRamework Of VEctorized and DIStributed data analytics) is an Open Source unified middleware implemented in C++ for NEC SX-Aurora TSUBASA. It covers a large part of Apache SPARK, implementing the same API for the domains Machine Learning, Matrix Libraries and Data Frame. Frovedis transparently supports multiple VE cards and VH servers by using MPI-based parallelism for scalable distributed processing. Frovedis is very easy-to-use as the following figure shows. Only a changed import line in the source file and two added lines for starting and stopping the MPI based Frovedis service are required.
This framework has been developed to fully utilize the vector architecture and in particular take advantage of the superior bandwidth of the SX-Aurora TSUBASA. It supports the MLlib and scikit-learn libraries and achieves speedups of 10 to 100 in standard CPU versus VE comparisons.
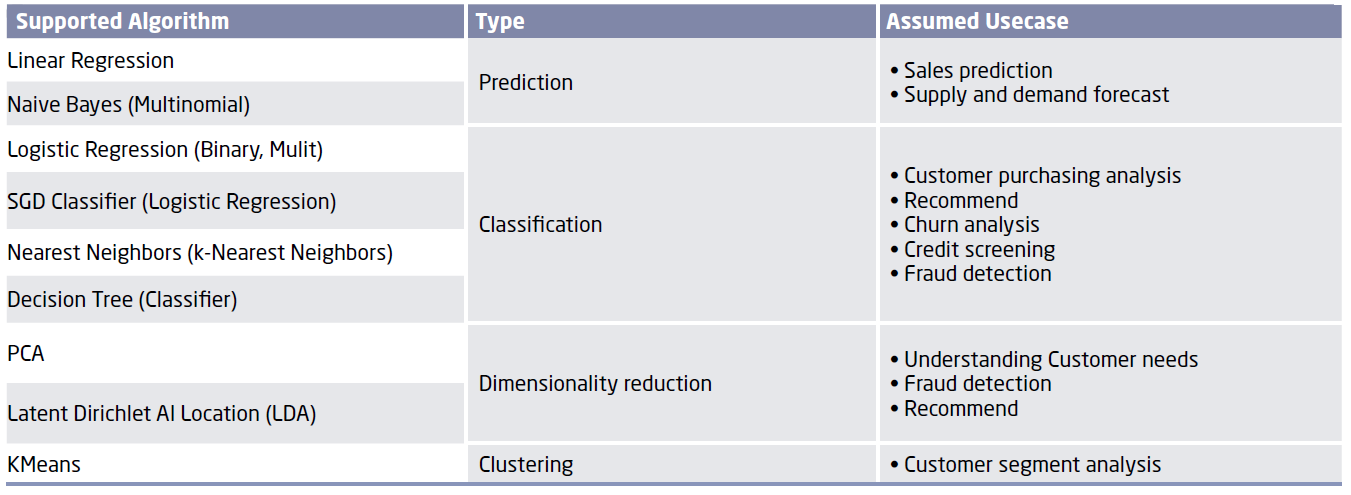
The Frovedis Machine Learning Library is implemented with Frovedis Core and Matrix Libraries and supports both dense and sparse data. The huge bandwidth of VE contributes to the high performance of the sparse algorithms that are key to large scale ML. The figure below is a snapshot of the growing list of MLlib supported algorithms.
Snapshot of list of supported algorithms in the ML library

Examples of real world use cases of ML algorithms
The following figure shows three examples from memory-intensive ML where the SX-Aurora TSUBASA vector architecture significantly increases the processing speed: (1) recommendation engines, (2) demand/price prediction, and (3) risk mitigation analysis.
Sustained performance advantages of Frovedis on SX-Aurora TSUBASA

Xeon Gold 6226: 12 cores/socket, 2 socket/node, CentOS 8.1
SX-Aurora TSUBASA: A311-8, VE Type 10BE
Spark: 3.0.0 for K-means and SVD, 2.2.1 for LR
Frovedis: as of 2020/09/08
DataFrame performance is also accelerated significantly, as demonstrated in TPC-H SF-20 benchmark runs shown below. The test comparing again a Xeon Gold 6226 are Q01: group by/aggregate, Q03: filter, join, group by/aggregate, Q05: filter, join, group by/aggregate (larger join), and Q06: filter, group by/aggregate.
TPC-H SF-20 benchmark acceleration by Frovedis on SX-Aurora TSUBASA
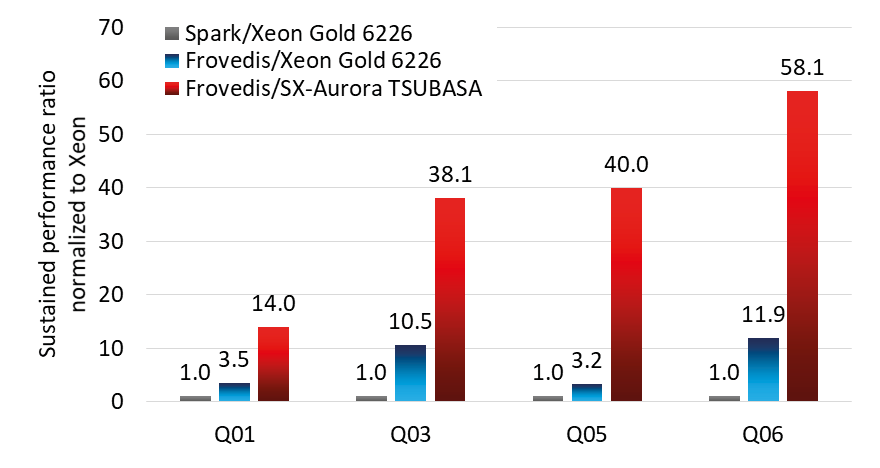
Xeon Gold 6226: 12 cores/socket, 2 socket/node, CentOS8.1
SX-Aurora TSUBASA: A311-8, VE Type 10BE, compiler 3.0.7, MPI 2.9.0
Spark: 3.0.0
Frovedis: as of 2020/09/08
One of the major fields for ML is “optimization”. For example, ML-methods are applied to optimize each location of 5G network base stations used for telecommunication. Frovedis on SX-Aurora TSUBASA reaches a shorter time to solution, it can therefore reduce the amount of HPC equipment needed for operational ML, and consequently the user can save budget, space, electricity, thus operational and maintenance costs.
5G Network Optimization by Frovedis on SX-Aurora TSUBASA
