Frovedis Machine Learning: Unsupervised Learning Dimensionality reduction using clustering and t-SNE Reduced learning time
May 10, 2022 Shoichiro Yokotani, Application Development Expert AI Platform division
Frovedis Machine Learning: Unsupervised Learning Dimensionality reduction using clustering and t-SNE Reduced learning time (compared to scikit-learn)
Unsupervised learning is a general term for learning to extract information from a data set that does not have any indicators of correct answers. In supervised learning, there is a set of output (correct answer) data corresponding to the input data. This allowed us to verify the correctness of the learning results. However, in unsupervised learning, there is no measure of correctness or incorrectness. It is generally difficult to judge whether the learning results are appropriate or not.
Unsupervised learning can be divided into two main categories. The first is clustering, which divides a dataset into groups according to their characteristics. For example, it can be used to group articles into political, economic, sports, etc. based on the similarity of words in individual news articles. The name of each group is not automatically assigned by unsupervised learning, so each group must be labeled by human judgment. The certainty of the grouped results also requires human judgment.
The second is data dimensionality reduction. Data sets with high-dimensional features are converted to lower dimensions. Data sets with high-dimensional features are difficult to understand by graphing their features. In such cases, dimensionality reduction is useful, such as creating important variables from high-dimensional features or transforming high-dimensional data into low-dimensional spatial data based on the distance between data in the high-dimensional space. Dimensionality reduction makes it easier to visually understand the features of the data.
As a sample of the unsupervised learning algorithm presented here, we will use a dataset of news articles that have been previously segmented into words and vectorized using Word2vec. As a first step, we use k-means clustering to group the words in the news articles. Next, we visualize the data features using t-SNE and clustering again using DBSCAN algorithm. We measure the training time for each learning algorithm using Frovedis and scikit-learn.
Clustering by t-SNE and k-means, DBSCAN (Comparison of learning time between scikit-learn version and Frovedis version)
Dataset used: Economic news articles vectorized by Word2vec after word segmentation
in [1]:
|
import numpy as np import pandas as pd from frovedis.mllib import Word2Vec from gensim.models import word2vec from sklearn.cluster import KMeans from collections import defaultdict from sklearn.preprocessing import StandardScaler import matplotlib.pyplot as plt import csv import sys, os, time, csv from frovedis.exrpc.server import FrovedisServer import warnings |
|
/home/user01/.local/lib/python3.6/site-packages/gensim/similarities/__init__.py:15: UserWarning: The gensim.similarities.levenshtein submodule is disabled, because the optional Levenshtein package |
Dataset used: Economic news articles vectorized by Word2vec after word segmentation
in [2]:
|
model = word2vec.Word2Vec.load("word2vec.finance_news_cbow500.model") #max_vocab = 50000000000000 vocab = list(model.wv.key_to_index.keys())[:] vectors = [model.wv[word] for word in vocab] |
Clustering with Frovedis k-means
in [3]:
|
from frovedis.mllib.cluster import KMeans as frovKM FrovedisServer.initialize("mpirun -np 2 {}".format(os.environ['FROVEDIS_SERVER'])) t1 = time.time() f_est = frovKM(n_clusters=8, init='random', algorithm='full', random_state=123, n_init=1).fit(vectors) t2 = time.time() FrovedisServer.shut_down() print("Frovedis KMeans train time: {:.3f} sec".format(t2-t1)) print(set(f_est.labels_)) u, counts = np.unique(np.array(f_est.labels_), return_counts=True) print(u, counts) |
Frovedis KMeans train time: 0.081 sec
{0, 1, 2, 3, 4, 5, 6, 7}
[0 1 2 3 4 5 6 7] [1756 2514 2775 1972 2478 2090 3905 2602]
in [4]:
|
cluster_labels = f_est.labels_ cluster_to_words = defaultdict(list) for cluster_id, word in zip(cluster_labels, vocab): cluster_to_words[cluster_id].append(word) for i in range(len(cluster_to_words.values())): print(list(cluster_to_words.keys())[i], list(cluster_to_words.values())[i][:25]) print("----------------------------------") |
6 ['u.s.', 'market', 'china', 'fed', 'economy', 'covid-19', 'investor', 'economic', 'global', 'growth', 'time', 'business', 'add', 'cut', 'far', 'get', 'think', 'move', 'continue', 'demand', 'people', 'well', 'world', 'policy', 'inflation']
----------------------------------
0 ['year', 'trade', 'rise', 'last', 'week', 'stock', 'month', 'price', 'new', 'expect', 'report', 'point', 'data', 'gain', 'dollar', 'high', 'yield', 'end', 'day', 'increase', 'accord', 'fell', 'close', 'show', 'wednesday']
----------------------------------
3 ['company', 'share', 'firm', 'group', 'announce', 'revenue', 'airline', 'france', 'corp', 'shareholder', 'maker', 'operate', 'stake', 'unit', 'co', 'giant', 'retailer', 'dividend', 'rival', 'electric', 'boeing', 'ltd', 'motor', 'chip', 'spain']
----------------------------------
7 ['bank', 'government', 'include', 'fund', 'plan', 'work', 'debt', 'use', 'issue', 'cost', 'tax', 'loan', 'finance', 'offer', 'source', 'pay', 'purchase', 'provide', 'public', 'benefit', 'program', 'rule', 'cash', 'account', 'reduce']
----------------------------------
2 ['donald trump', 'deal', 'country', 'president', 'tell', 'u.k.', 'meet', 'state', 'e.u.', 'official', 'call', 'talk', 'news', 'comment', 'two', 'joe biden', 'administration', 'statement', 'agreement', 'agree', 'national', 'foreign', 'election', 'italy', 'decision']
----------------------------------
1 ['analyst', 'investment', 'chief', 'financial', 'economist', 'note', 'capital', 'head', 'strategist', 'equity', 'security', 'executive', 'senior', 'research', 'new york', 'manager', 'write', 'strategy', 'director', 'partner', 'management', 'goldman sachs', 'manage', 'portfolio', 'jpmorgan']
----------------------------------
5 ['tariff', 'industry', 'supply', 'american', 'home', 'goods', 'order', 'worker', 'production', 'health', 'export', 'product', 'lockdown', 'international', 'import', 'build', 'restriction', 'travel', 'canada', 'power', 'reopen', 'region', 'city', 'impose', 'producer']
----------------------------------
4 ['service', 'technology', 'value', 'tech', 'list', 'ceo', 'apple', 'invest', 'bitcoin', 'ipo', 'name', 'customer', 'cryptocurrency', 'valuation', 'online', 'amazon', 'tesla', 'launch', 'digital', 'medium', 'platform', 'hedge fund', 'facebook', 'spac', 'model']
----------------------------------
Clustering with scikit-learn k-Means
in [5]:
|
from sklearn.cluster import KMeans as skKM t1 = time.time() s_est = skKM(n_clusters=8, init='random', algorithm='full', random_state=123, n_init=1).fit(vectors) t2 = time.time() print("scikit-learn KMeans train time: {:.3f} sec".format(t2-t1)) print(set(s_est.labels_)) |
Dimensionality reduction using Frovedis t-SNE
{0, 1, 2, 3, 4, 5, 6, 7}
Clustering with scikit-learn k-Means
in [6]:
|
from frovedis.mllib.manifold import TSNE as frovTSNE FrovedisServer.initialize('"mpirun -np 2 " + os.environ['"FROVEDIS_SERVER"]) t1 = time.time() f_est = frovTSNE(n_components=2, method='"exact").fit_transform(vectors) t2 = time.time() print('"Frovedis t-SNE train time: {:.3f} sec".format(t2-t1)) FrovedisServer.shut_down() |
Frovedis t-SNE train time: 18.727 sec
Dimensionality reduction using scikit-learn t-SNE
in [7]:
|
from sklearn.manifold import TSNE as skTSNE t1 = time.time() s_est = skTSNE(n_components=2, method='barnes_hut').fit_transform(vectors) t2 = time.time() print("scikit-learn t-SNE train time: {:.3f} sec".format(t2-t1)) |
scikit-learn t-SNE train time: 198.753 sec
Graphing data after dimensionality reduction using Frovedis t-SNE
in [8]:
|
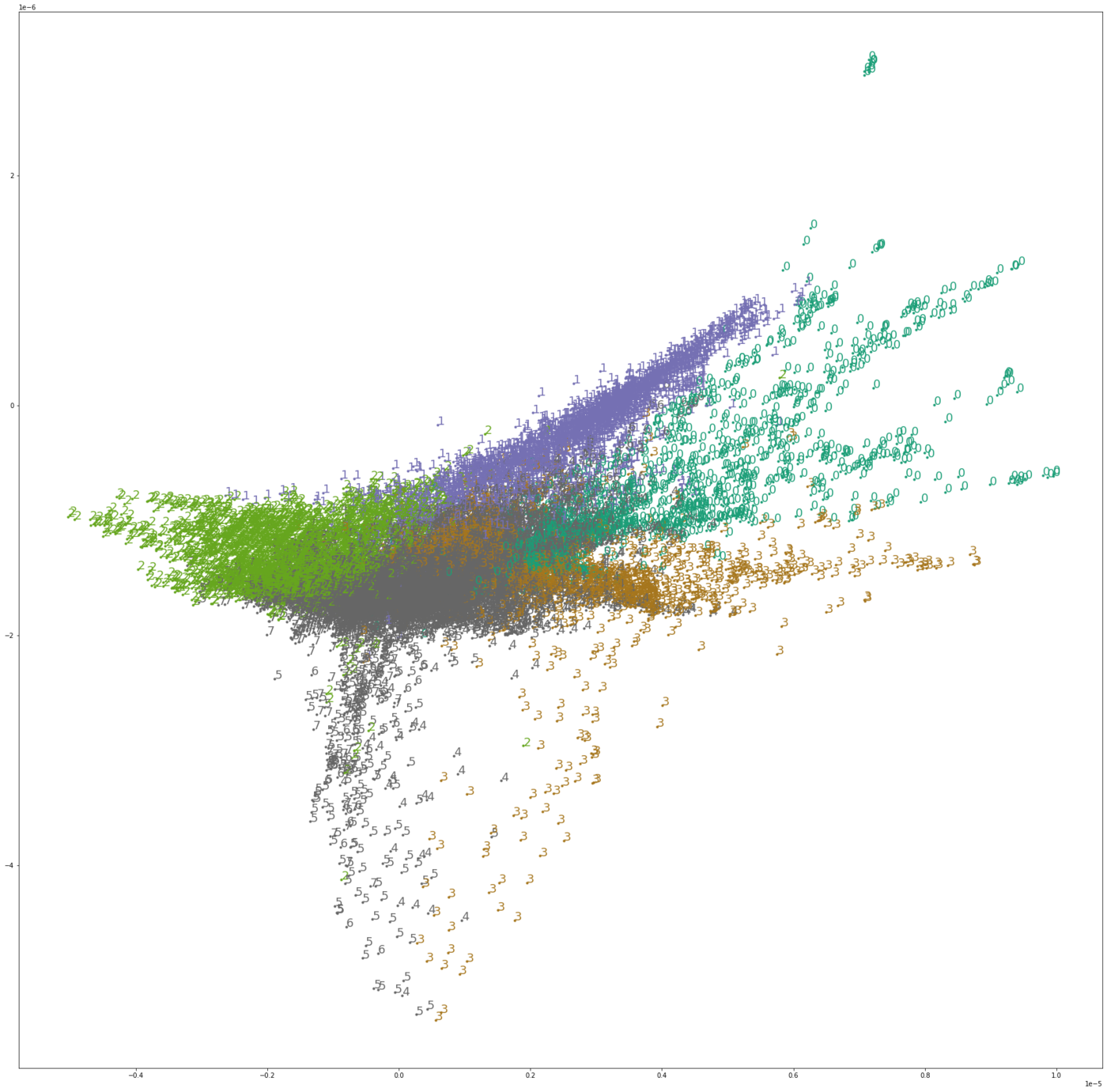
FrovedisServer.initialize("mpirun -np 2 " + os.environ["FROVEDIS_SERVER"]) clustered = frovKM(n_clusters=8, init='random', algorithm='full', random_state=123, n_init=1).fit_predict(vectors) FrovedisServer.shut_down() fig, ax = plt.subplots(figsize=(30, 30)) cmap = plt.get_cmap('Dark2') for i in range(f_est.shape[0]): cval = cmap(clustered[i] / 4) ax.scatter(f_est[i][0], f_est[i][1], marker='.', color=cval) ax.annotate(cluster_labels[i], xy=(f_est[i][0], f_est[i][1]), color=cval, fontsize=18) plt.plot() |
in [9]:
|
from frovedis.mllib.cluster import DBSCAN as frovDB FrovedisServer.initialize("mpirun -np 2 {}".format(os.environ['FROVEDIS_SERVER'])) t1 = time.time() f_est = frovDB(eps=1.5, metric="euclidean", min_samples=5, algorithm="brute").fit(vectors) t2 = time.time() print("Frovedis DBSCAN train time: {:.3f} sec".format(t2-t1)) u, counts = np.unique(np.array(f_est.labels_), return_counts=True) print("labels_ \n",u) print("counts_ \n",counts) cluster_labels = f_est.labels_ cluster_to_words = defaultdict(list) for cluster_id, word in zip(cluster_labels, vocab): cluster_to_words[cluster_id].append(word) for i in range(len(cluster_to_words.values())): print(list(cluster_to_words.keys())[i], list(cluster_to_words.values())[i][:25]) print("----------------------------------") FrovedisServer.shut_down() |
Frovedis DBSCAN train time: 0.204 sec
labels_
[-1 0 1 2 3 4 5 6 7]
counts_
[11852 5 8195 12 6 8 8 3 3]
-1 ['u.s.', 'year', 'market', 'trade', 'china', 'company', 'bank', 'rise', 'fed', 'last', 'week', 'economy', 'stock', 'covid-19', 'investor', 'price', 'economic', 'new', 'expect', 'share', 'report', 'global', 'growth', 'point', 'data']
----------------------------------
2 ['month', 'march', 'april', 'june', 'july', 'december', 'january', 'september', 'february', 'october', 'august', 'november']
----------------------------------
0 ['wednesday', 'thursday', 'monday', 'tuesday', 'friday']
----------------------------------
1 ['get', 'think', 'well', 'need', 'look', 'start', 'many', 'result', 'way', 'begin', 'mean', 'potential', 'worry', 'suggest', 'thing', 'believe', 'happen', 'possible', 'appear', 'seem', 'come', 'reason', 'probably', 'particularly', 'something']
----------------------------------
3 ['tdk', 'komatsu', 'keyence', 'sumco', 'yuden', 'taiyo']
----------------------------------
4 ['26-week', '13-week', '4-week', '8-week', '119-day', '42-day', '154-day', '105-day']
----------------------------------
5 ['razaqzada', 'fawad', 'forex.com', 'otunuga', 'rhona', 'briesemann', 'lukman', 'oconnell']
----------------------------------
6 ['btc', 'eth', 'utc']
----------------------------------
7 ['wakatabe', 'noguchi', 'masazumi']
----------------------------------
Clustering with scikit-learn DBSCAN
in [10]:
|
from frovedis.mllib.cluster import DBSCAN as frovDB FrovedisServer.initialize("mpirun -np 2 {}".format(os.environ['FROVEDIS_SERVER'])) t1 = time.time() f_est = frovDB(eps=1.5, metric="euclidean", min_samples=5, algorithm="brute").fit(vectors) t2 = time.time() print("Frovedis DBSCAN train time: {:.3f} sec".format(t2-t1)) u, counts = np.unique(np.array(f_est.labels_), return_counts=True) print("labels_ \n",u) print("counts_ \n",counts) cluster_labels = f_est.labels_ cluster_to_words = defaultdict(list) for cluster_id, word in zip(cluster_labels, vocab): cluster_to_words[cluster_id].append(word) for i in range(len(cluster_to_words.values())): print(list(cluster_to_words.keys())[i], list(cluster_to_words.values())[i][:25]) print("----------------------------------") FrovedisServer.shut_down() |
scikit-learn DBSCAN train time: 5.830 sec
labels_
[-1 0 1 2 3 4 5 6 7]
counts_
[11852 5 8195 12 6 8 8 3 3]
-1 ['u.s.', 'year', 'market', 'trade', 'china', 'company', 'bank', 'rise', 'fed', 'last', 'week', 'economy', 'stock', 'covid-19', 'investor', 'price', 'economic', 'new', 'expect', 'share', 'report', 'global', 'growth', 'point', 'data']
----------------------------------
2 ['month', 'march', 'april', 'june', 'july', 'december', 'january', 'september', 'february', 'october', 'august', 'november']
----------------------------------
0 ['wednesday', 'thursday', 'monday', 'tuesday', 'friday']
----------------------------------
1 ['get', 'think', 'well', 'need', 'look', 'start', 'many', 'result', 'way', 'begin', 'mean', 'potential', 'worry', 'suggest', 'thing', 'believe', 'happen', 'possible', 'appear', 'seem', 'come', 'reason', 'probably', 'particularly', 'something']
----------------------------------
3 ['tdk', 'komatsu', 'keyence', 'sumco', 'yuden', 'taiyo']
----------------------------------
4 ['26-week', '13-week', '4-week', '8-week', '119-day', '42-day', '154-day', '105-day']
----------------------------------
5 ['razaqzada', 'fawad', 'forex.com', 'otunuga', 'rhona', 'briesemann', 'lukman', 'oconnell']
----------------------------------
6 ['btc', 'eth', 'utc']
----------------------------------
7 ['wakatabe', 'noguchi', 'masazumi']
----------------------------------
We can see that the word groups grouped by k-means are in eight coherent groups that are likely to be related to the world economy, trade, financial markets, and corporate information. DBSCAN, on the other hand, creates two large groups of words that could be included in any article. We can see that the contents of the groups vary greatly depending on the clustering algorithm.
The following table summarizes the time required for each learning process. In particular, there is a large difference in learning time for t-SNE. Furthermore, while Frovedis uses method="exact" for more accurate computation (more computation and longer time), scikit-learn uses method='barnes_hut' which reduces computation by approximation. For this dataset size, it took about 5 hours without scikit-learn's approximate calculation option. This is not practical.
| learning algorithm | Frovedis (sec) | scikit-learn(sec) | Ratio |
|---|---|---|---|
| t-SNE | 18.73 | 198.75 | x10.6 |
| k-means | 0.08 | 0.68 | x8.5 |
| DBSCAN | 0.20 | 5.83 | x29.2 |
Depending on the distribution shape of the data set, clustering algorithms may or may not be suitable. It is often time-consuming to repeatedly train multiple combinations of parameters to determine which algorithm is best suited for a given analysis. With SX-Aurora TSUBASA and Frovedis, we can reduce this burden in machine learning.