Hybrid MPI: Combining the Strengths of VE and VH
Oct 2022, Patrick Lipka, NEC Deutschland HPCE
Hybrid MPI: Combining the Strengths of VE and VH
Achieving great application performances on NEC SX-Aurora TSUBASA can be easy if the code can be vectorized by the compilers. But what to do with big amounts of scalar work for which vector processors aren’t a good fit? One way to deal with this is offloading it to the vector host CPU using NECs offloading frameworks which requires additional implementation effort. In this blog post I would like to show how easy speedups of MPI-parallelized applications can be obtained if split computational work is split from unvectorizable tasks.
Reminder: NEC MPI
| mpincc | C Aurora Compiler wrapper |
| mpinc++ | C++ Aurora Compiler wrapper |
| mpinfort | Fortran Aurora Compiler wrapper |
| Syntax: | |
| $ <compiler> <flags> <source> | |
| Examples: | |
| $ mpinfort –o test.x test.F90 | # compilation of Fortran |
| $ mpinfort –c test.F90 | # object creation |
| $ mpinfort –o test.x test1.o test2.o | # linking |
Using the NEC MPI compiler wrappers, it is easy to compile our test code:
| #include <mpi.h> #include <stdio.h> int main(int argc, char **argv) { MPI_Init(&argc, &argv); int my_rank, namel; char name[MPI_MAX_PROCESSOR_NAME]; MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Get_processor_name(name, &namel); printf("Process %2d is running on %s\n", my_rank, name); MPI_Finalize(); return 0; $ mpincc –o mpi_VE mpi.c |
We can use the same compiler wrappers to compile the program for the vector host. We just need to add the -vh flag and tell NEC MPI which compiler should be used:
| $ export NMPI_CC_H=gcc $ mpincc –vh –o mpi_VH mpi.c |
The following examples will use the executables compiled from this test code.
Running programs on the Vector Engine
-np, -n, -c determine the number of processes to create, -v prints out process placement| $ mpirun –np 6 –v ./mpi_VE mpid: Creating 6 processes of './mpi_VE' on VE 0 of local host node0 Process 0 is running on node0, ve id 0 Process 1 is running on node0, ve id 0 Process 2 is running on node0, ve id 0 Process 3 is running on node0, ve id 0 Process 4 is running on node0, ve id 0 Process 5 is running on node0, ve id 0 |

|
$ mpirun –ve 0-1 –vennp 3 ./mpi_VE Process 0 is running on node0, ve id 0 Process 1 is running on node0, ve id 0 Process 2 is running on node0, ve id 0 Process 3 is running on node0, ve id 1 Process 4 is running on node0, ve id 1 Process 5 is running on node0, ve id 1 |


Running programs on the Vector Host
-vh executes the program on the VH. It needs to be compiled for the target architecture
|
$ mpirun -vh –np 6 ./mpi_VH Process 0 is running on node0, VH Process 1 is running on node0, VH Process 2 is running on node0, VH Process 3 is running on node0, VH Process 4 is running on node0, VH Process 5 is running on node0, VH |
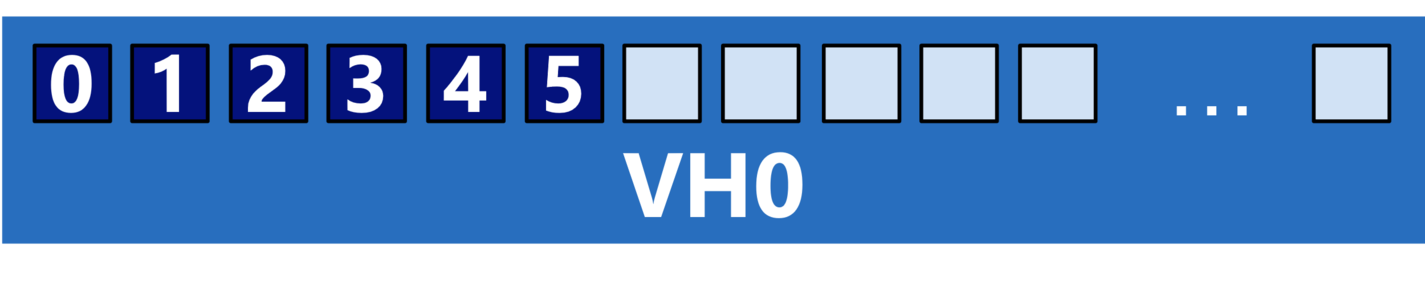
-nnp, -ppn –npernode, -N determine the number of processes per VH
|
$ mpirun -vh –np 3 ./mpi_VH Process 0 is running on node0, VH Process 1 is running on node0, VH Process 2 is running on node0, VH Process 3 is running on node1, VH Process 4 is running on node1, VH Process 5 is running on node1, VH |
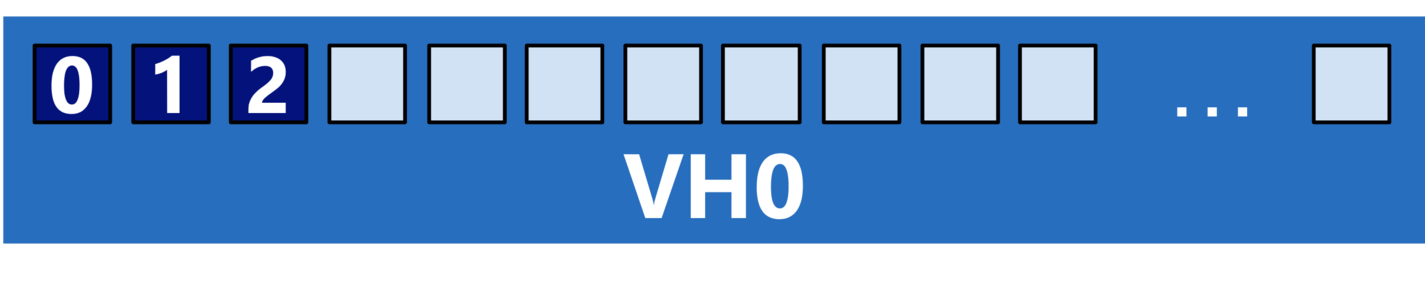
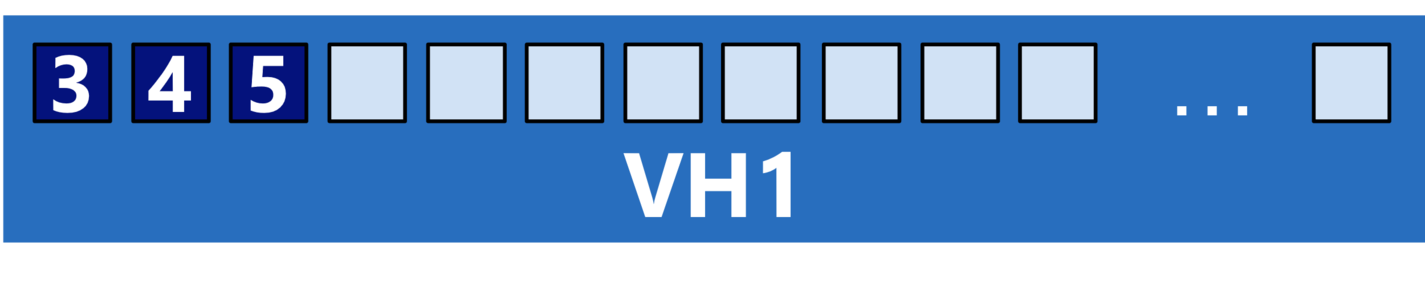
Running programs across VE and VH
VE/VH hybrid execution is easily achieved by chaining VE and VH commands for the corresponding executables:
|
mpirun -vh -np 2 ./mpi_VH : \ -ve 0-1 -vennp 1 ./mpi_VE : \ -ve 2-3 -vennp 2 ./mpi_VE : \ -vh -np 1 ./mpi_VH Process 0 is running on node0, VH Process 1 is running on node0, VH Process 2 is running on node0, ve id 0 Process 3 is running on node0, ve id 1 Process 4 is running on node0, ve id 2 Process 5 is running on node0, ve id 2 Process 6 is running on node0, ve id 3 Process 7 is running on node0, ve id 3 Process 8 is running on node0, VH |
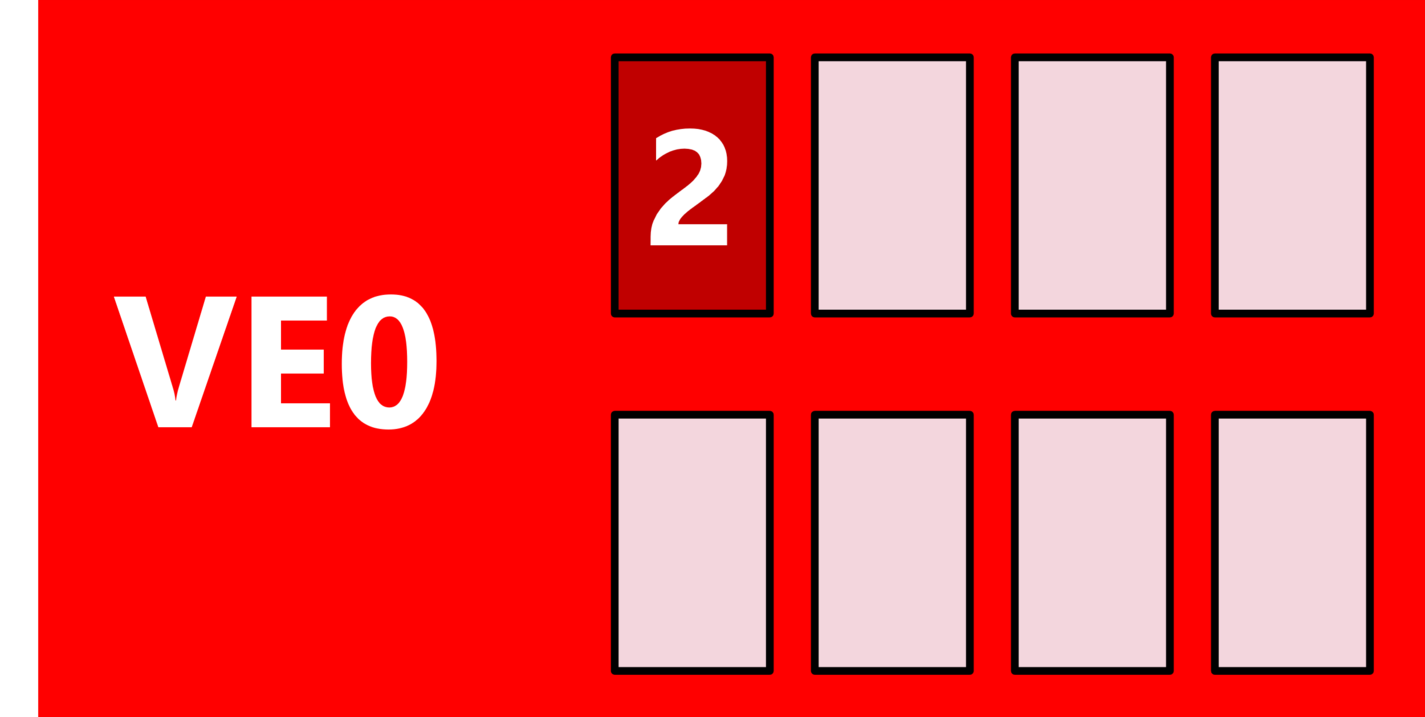


Optimization Opportunity: I/O processes on the Vector Host
The MPI features shown above can be used to easily split work between the Vector Engine and the Vector Host. One just needs to compile the code twice and adjust the mpirun command.
This gives us the opportunity to combine the strengths of both architectures by placing MPI ranks with different types of work on the processor that fits best.
One example of such a setup is commonly seen in meteorological codes: A separate I/O server is implemented which is a set of MPI ranks that call I/O routines, distribute data to the compute ranks and do some bookkeeping while the compute ranks are busy. As this is purely scalar work, it won’t benefit from the strengths of a vector CPU and is therefore well-suited for being run on the Vector Host.
Let’s have a look at two real life examples were NEC customers implemented such setups.
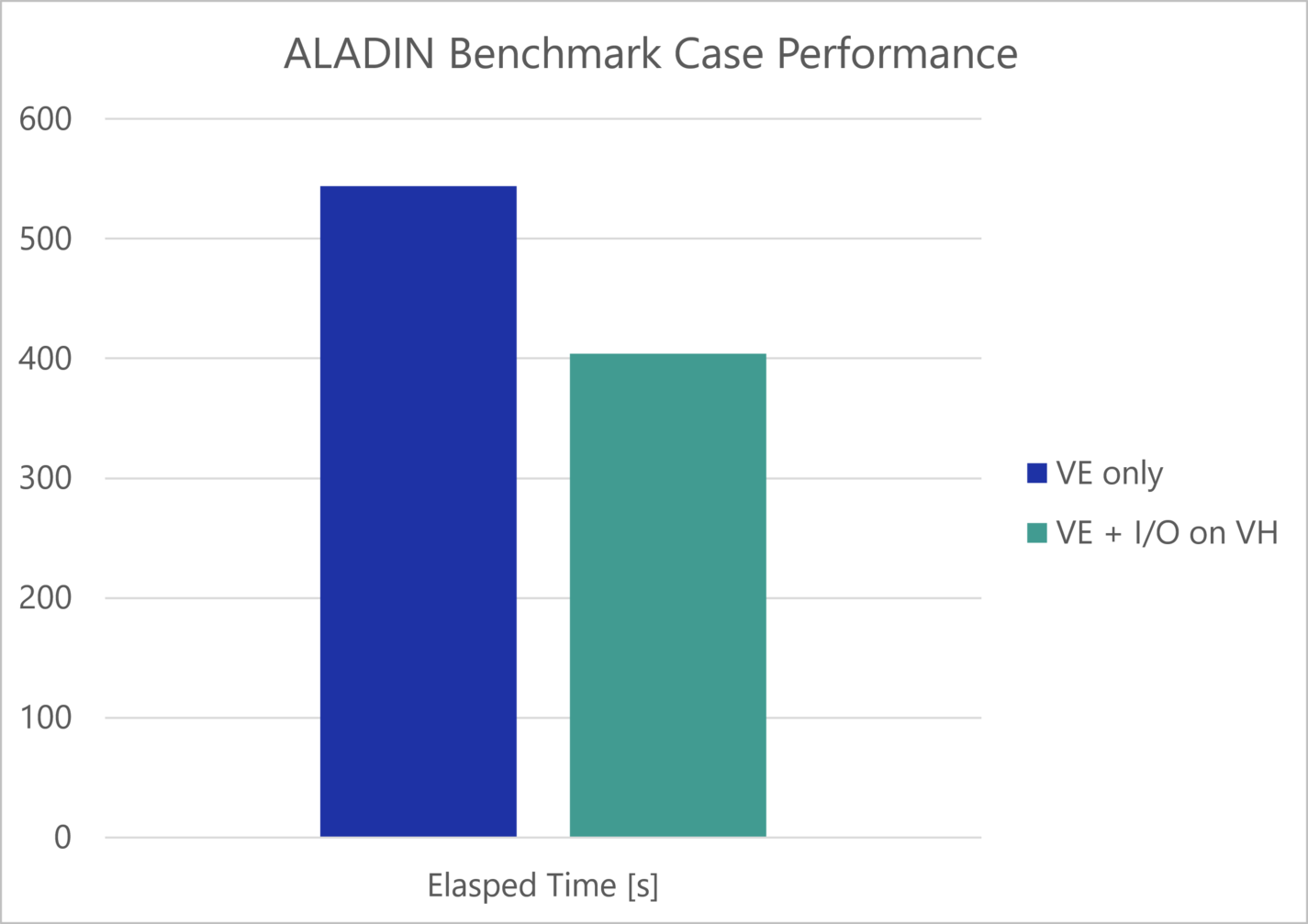
Real-Life Example: ALADIN code at CHMI
The preparation was very easy as there are already optimized setups for both the Vector Engine and x86 CPUs. The x86 compilation just needed to be adapted to use NEC MPI compiler wrappers instead of Intel MPI. ALADIN contains a native implementation of an I/O server that just needed to be activated using the corresponding namelist settings and adjusting the mpirun command:
|
mpirun -np $NPROC $VE_EXE :\ -vh -vpin -pin_mode scatter -nnp $IO_PER_VH ${VH_EXE} |
Using a setup of 4 nodes with 8 VEs of type 20B per Node and AMD 7402 as VH CPU, the 12h forecast benchmark performance could be improved by approximately 25%.
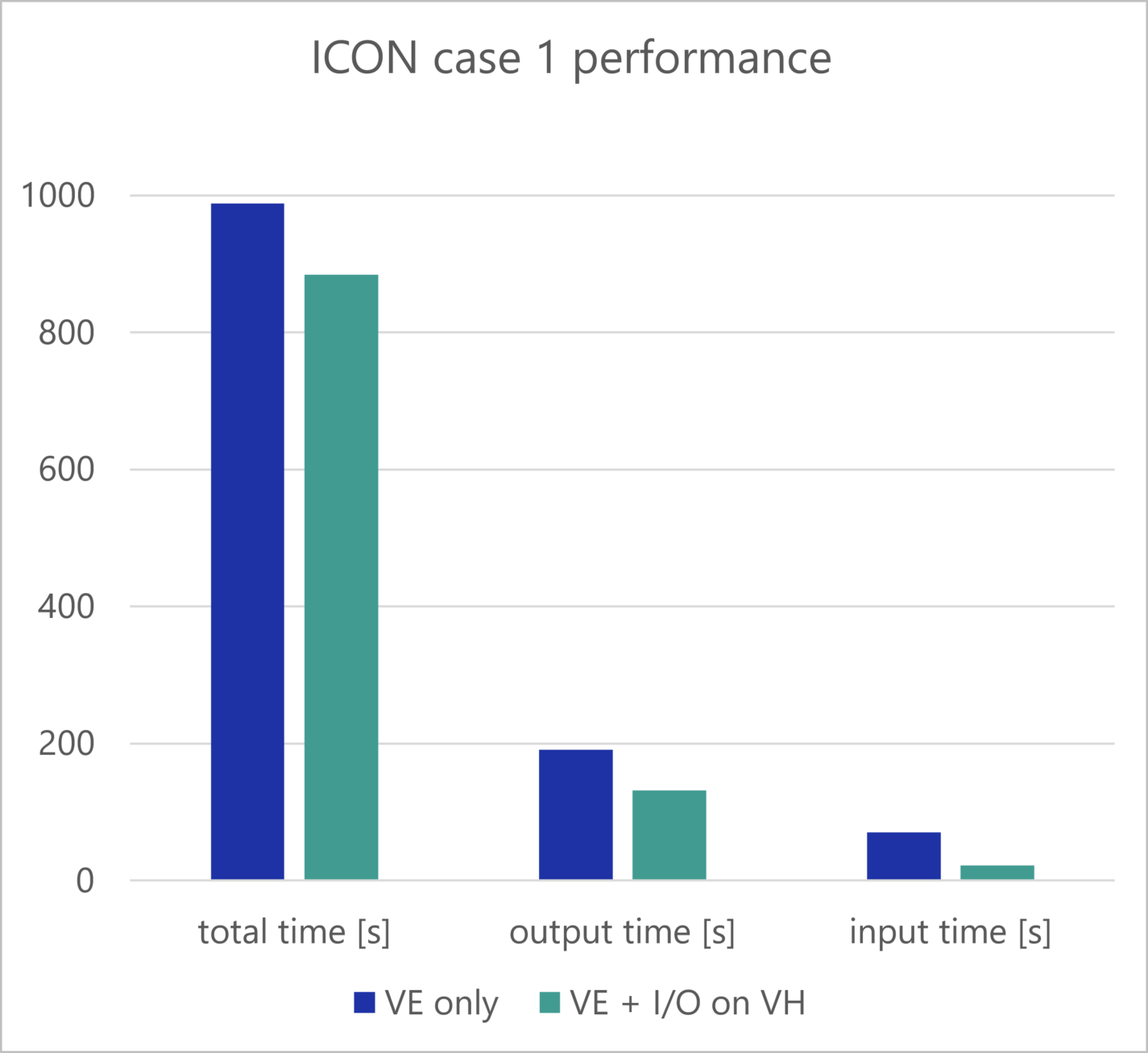
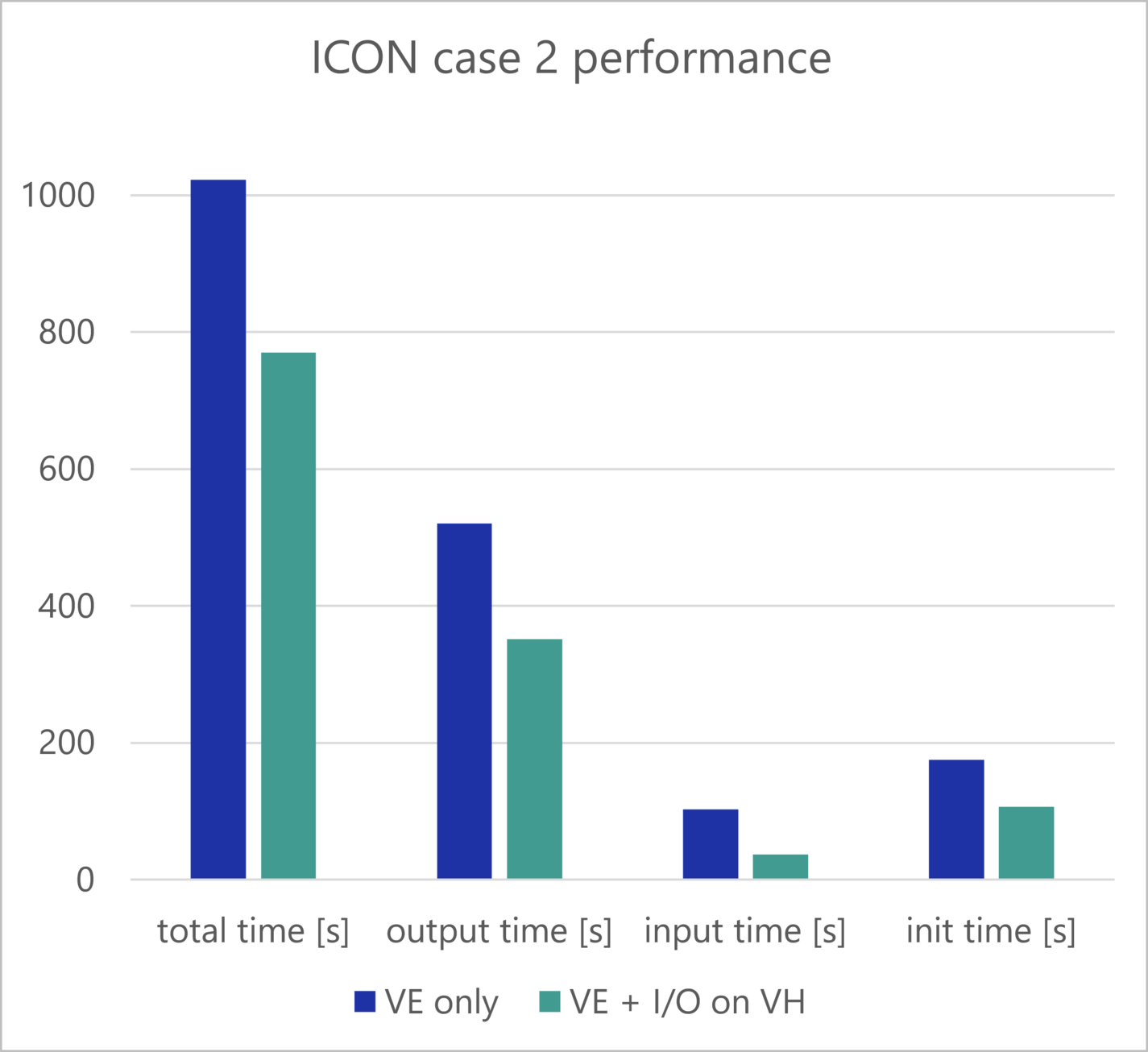
Real-Life Example: ICON code at DWD
Moving the scalar initialization and I/O work of ICON to the Vector Host required some porting work as parts of the communication between the processes has been done using byte streams which are incompatible between different architectures. Switching to proper MPI datatypes solved this problem.
Aside from that, the preparation of the setup was straight forward as there are already optimized setups for the Vector Engine and x86 CPUs. Again, the compiler wrappers needed to be changed to the NEC MPI ones and the Vector Host process invocation needed to be added to the mpirun command.
This setup has been tested with two benchmark cases. Note that the I/O processes consume big amounts of energy in the second case which prohibits one from using all VE cores in the original setup.
- benchmark case 1: 11 VEs type 10AE, 1 MPI process per core (+5 processes on AMD VH CPU)
- benchmark case 2:
- VE-only: 7 nodes, 406 VE processes, per node: 7 VEs with 8 computation processes + 1 VE with 2 I/O processes due to very high memory usage of I/O processes
- Hybrid: 7 nodes, 448 VE processes, per node: 1 MPI process per core (now possible due to less memory consumption) + 2 I/O processes on the VH
Verdict
The ability of NEC MPI to run applications across Vector Engines and Vector Hosts enables users to easily assign MPI ranks with different types of work to the processor that fits best.
The real-life examples show that significant speedups can be obtained using minor porting efforts.