SX-Aurora TSUBASA Architecture
NEC SX-Aurora TSUBASA Architecture
NEC Vector Engine Processor
The NEC Vector Engine Processor of the new system has eight to ten independent vector cores.
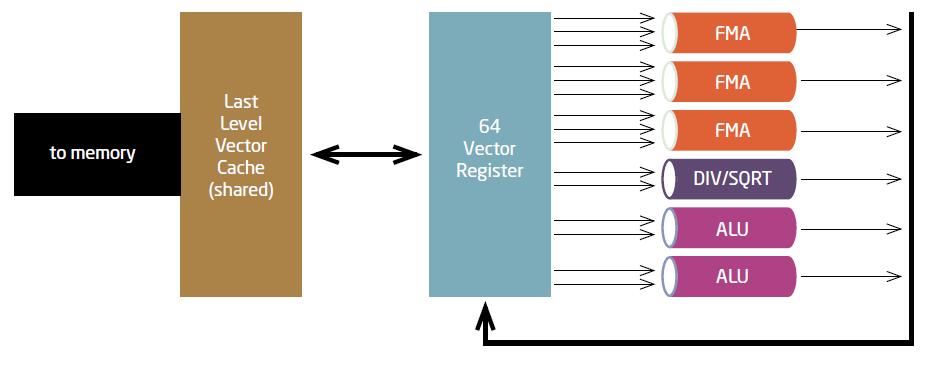
There are 64 fully functional vector registers per core, which can feed the functional units or which receive results from those.
This is the first significant and important enhancement compared to the previous SX-systems, which only had eight vector registers, plus 64 so-called vector-data-registers used for intermediate results, but lacking the full functionality of a vector-register, namely to act as an input to the functional units.
So in the future the compiler will have a lot more options to optimize the register usage and consequently this will enhance the efficiency of system.
The vector registers has 256 entries of 8-Byte-width, thus being able to handle double-precision data at full speed. So the full set of registers represents 128 kByte of data readily available for computations at the speed of a register!
The system has three FMA-units, plus one for divide and sqrt, per core. FMA stands for “floating-point multiply add”, and reflects an expression like a * b + c.
The importance of the pipe for divide and sqrt is often underestimated. Indeed such operations are not dominating in normal scientific applications. But if there are cases where they are needed, they often prove to be limiting, or at least contribute significantly to the calculations. Other architectures emulate such operations by a software-approximation, which can be time consuming.
In order to provide a high computing capability those pipes are designed with a 32-way parallelism, means, each pipe produces 32 results per cycle.
Traditionally only add- and multiply-operations are counted when computing the peak-performance of an architecture. For the new system this is then
3 * 2 * 32 = 192 double precision floating point operations per cycle
There are more pipes for fixed-point arithmetic and logical operations. And all together they are fully connected to the vector-registers by a fully non-blocking crossbar.
NEC SX-Aurora TSUBASA Memory
The NEC Vector Engine Processor has a newly developed shared "Last-Level-Cache" (LLC), the first shared vector cache ever. This shared LLC serves all cores simultaneously, and has a "write-back" policy, which means coherency between different cores, LLC and memory is always easily ensured. At the same time this kind of architecture lends itself easily to a shared memory parallelization, by autoparallelization or OpenMP, while MPI would be used to parallelize over different Engines. The last level cache has a line-size of 128 bytes, and some additional features are implemented to increase the efficency for strided stores or scatter operations.
NEC utilizes the second generation of the so called "High Bandwidth Memory" standard, HBM2. A HBM2 memory block is realized by stacking four or eight dies together, and it achieves up to 200 GB/s bandwidth while providing either 4 or 8 GB of capacity. Six of these memory blocks and the Vector Engine Processor are connected by means of a so-called "Silicon interposer", a special die to mount on and that connects memory and processor. They provide a total of 24 GB to 48 GB per Vector Engine and an outstanding 1.53 TB/s bandwidth, the best bandwidth in the market.
NEC Vector Engine Processor with six High Bandwidth Memory (HBM2)
NEC SX-Aurora TSUBASA Interconnect
The NEC Vector Engine can communicate with other Vector Engines or x86 CPUs over shared memory, PCI Express or a high speed network.
