VEDA: Best practices to use hybrid programming on the NEC SX-Aurora TSUBASA
Oct. 2022 - Nicolas Weber - NEC Laboratories Europe
VEDA: Best practices to use hybrid programming on the NEC SX-Aurora TSUBASA
The Vector Engine Driver API (VEDA) was developed to enable easy porting of existing CUDA applications to NEC's SX-Aurora TSUBASA. While the API enables a smooth transition between the different architectures, there are unique features that require special attention, to achieve optimal performance.
In this article we present multiple methods to improve your code. First, we explain how to use C++ function overloading and templates. Second, we show how to make best use of the unique features of VEDAdeviceptrs. Third, we explain our improvements for VEDA's memset and memcopy operations, that can also improve your own code.
1. Using C++ function overloading and templates with VEDA
Using C++ function overloading and templates in device code on VEDA is possible, but requires some additional effort. The problem is caused by name mangling. Mangling is used in C++ to distinguish different implementations with the same function name, but different function arguments or template parameters. Let's take a look at the example in Listing 1.
| int func(int A); int func(float B); |
Here we overload the function func with two data types: int and float. In order to distinguish these two functions, the compiler gives them unique names: _Z4funci and _Z4funcf. The _Z implies a C++ function name, the 4 says that a name with 4 letters (func) follows. All remaining are the function parameters, in this case i indicates int and the f indicates float.
So in order to use these C++ function names within VEDA, you have to load it using vedaModuleGetFunction(&func_int, module, "_Z4funci"); to get the VEDAfunction of the int version. Unfortunately, in your code you manually need to distinguish between the different function pointers. But, there are several methods available that can ease your pain.
1.1 Solution 1: extern "C" function wrapper
First, we look on how to simplify the problem of having mangled names. Especially in functions with lots of arguments this will otherwise be tedious to maintain. The most simple solution is to use function wrappers within your VE code, that wrap your C++ function into an extern "C" function, that has a human readable name. This can easily be done with preprocessor macros.
| int func(int A); int func(float B); #define WRAP(T) extern "C" int func_##T(T A) { return func(A); } WRAP(int) WARP(float) |
And then you use func_int and func_float to identify your functions within your VEDA code. While this is very easy to implement, it can become cumbersome when you have lots of combinations to implement.
1.2 Solution 2: dispatching function
Assuming we have the following function template, which allows many different implementations.
| template <int A, int B, typename T> void gemm(Ctx*, long, long, long, long, double, double, void const*, void const*, void*); |
Using a separate extern "C" function for every possible combination seems impractical. Let's say we allow the values A = [2], B = [3, -3, -4] and T = [float, double], which already results in 6 different combinations. With a rather small effort you can create a dispatching function on the device, that chooses the correct function at runtime.
| extern "C" void gemm(const int A, const int B, const int T, ...) { if(A == 2) { if(B == 3) { if(T == 0) gemm<2, 3, double>(...); else: gemm<2, 3, float >(...); } else if(B == -3) { if(T == 0) gemm<2, -3, double>(...); else: gemm<2, -3, float >(...); } else if(B == -4) { if(T == 0) gemm<2, -4, double>(...); else: gemm<2, -4, float >(...); } } } |
This method removes any handling of name mangling and only has a very small performance penalty at runtime. You can see this pattern implemented in our VEDA-Tensors compute-library to chose the correct operators and data types within our SX-Aurora device integrations for PyTorch and TensorFlow.
1.3 Solution 3: mangled name lookup
While function demangling is easy, there is no standard way of determining the name mangling of a function (see this article). In principle every compiler has it's own set of rules for mangling. Especially name substitution rules complicate the process.
Therefore another solution is to find your mangled names after compiling your device code. But before we can do this, we need to ensure that all functions have been instantiated in the device code. The problem is, that function templates are just a description and the compiler needs to be explicitly told to build it for given template arguments. While this happens automatically when you call the specific function in your code, the NCC compiler doesn't know that you want to call the function from within VEDA. Therefore we first need to instantiate all combinations of templates we want to have. Again, this can be done nicely using the C preprocessor.
| #define INSTANTIATE_ABC(A, B, T)\ template void gemm #define INSTANTIATE_AB(A, B)\ INSTANTIATE_ABC(A, B, float)\ INSTANTIATE_ABC(A, B, double) #define INSTANTIATE_A(A)\ INSTANTIATE_AB(A, 3)\ INSTANTIATE_AB(A, -3)\ INSTANTIATE_AB(A, -4) #define INSTANTIATE()\ INSTANTIATE_A(2) INSTANTIATE() #undef INSTANTIATE #undef INSTANTIATE_A #undef INSTANTIATE_AB #undef INSTANTIATE_ABC |
Next we need to implement a mechanism to choose the correct mangled name in VEDA. For this we use the command-line tool nm to get our mangled names. With nm library_name.so | grep " T " you get a list of all public symbols within your library.
| 0000000000018380 T some_extern_c_function 0000000000010a20 T _Z4gemmILi2ELi3EdEvP3CtxllllddPKvS3_Pv 0000000000010890 T _Z4gemmILi2ELi3EfEvP3CtxllllddPKvS3_Pv 0000000000010000 T _Z4gemmILi2ELin3EdEvP3CtxllllddPKvS3_Pv 000000000000fa90 T _Z4gemmILi2ELin3EfEvP3CtxllllddPKvS3_Pv 0000000000010700 T _Z4gemmILi2ELin4EdEvP3CtxllllddPKvS3_Pv 0000000000010570 T _Z4gemmILi2ELin4EfEvP3CtxllllddPKvS3_Pv |
When adding the -C flag, we get the demangled names.
| 0000000000018380 T some_extern_c_function 0000000000010a20 T void gemm<2, 3, double>(Ctx*, long, long, long, long, double, double, void const*, void const*, void*) 0000000000010890 T void gemm<2, 3, float>(Ctx*, long, long, long, long, double, double, void const*, void const*, void*) 0000000000010000 T void gemm<2, -3, double>(Ctx*, long, long, long, long, double, double, void const*, void const*, void*) 000000000000fa90 T void gemm<2, -3, float>(Ctx*, long, long, long, long, double, double, void const*, void const*, void*) 0000000000010700 T void gemm<2, -4, double>(Ctx*, long, long, long, long, double, double, void const*, void const*, void*) 0000000000010570 T void gemm<2, -4, float>(Ctx*, long, long, long, long, double, double, void const*, void const*, void*) |
Now you can choose the correctly mangled name, for the exact function you are looking for. Next we implement a function that returns us the correct name, as shown in Listing 8.
| #include template constexpr const char* get_function_name(void) { static_assert(A == 2); static_assert(B == 3 || B == -3 || B == -4); static_assert(std::is_same #define IF(A, B, C, NAME)\ if constexpr (A == a && B == b && std::is_same return NAME; IF(2, 3, double, "_Z4gemmILi2ELi3EdEvP3CtxllllddPKvS3_Pv") IF(2, 3, float, "_Z4gemmILi2ELi3EfEvP3CtxllllddPKvS3_Pv") IF(2, -3, double, "_Z4gemmILi2ELin3EdEvP3CtxllllddPKvS3_Pv") IF(2, -3, float, "_Z4gemmILi2ELin3EfEvP3CtxllllddPKvS3_Pv") IF(2, -4, double, "_Z4gemmILi2ELin4EdEvP3CtxllllddPKvS3_Pv") IF(2, -4, float, "_Z4gemmILi2ELin4EfEvP3CtxllllddPKvS3_Pv") #undef IF } template VEDAresult get_function(VEDAfunction* func, int A, int B, VEDAmodule mod) { VEDAfunction func; const char* name = [A, B] { if(A == 2) switch(B) { case 3: return get_function_name<2, 3, T>(); case -3: return get_function_name<2, -3, T>(); case -4: return get_function_name<2, -4, T>(); } } return ""; // will cause 'VEDA_ERROR_FUNCTION_NOT_FOUND' }(); return vedaModuleGetFunction(func, mod, name); } |
This code evaluates get_function_name<...>() already at compile time, so there is no performance penalty when using this approach. Further, the static_assert(...) checks at compile time for valid values.
1.4 Summary
We have shown three methods that allow to use C++ function overloading and templates with VEDA. However, all of these methods require some manual labor. At NEC Laboratories Europe we are investigating easier methods to enable C++ function overloading and templates directly within the VEDAfunction-API for a future version of VEDA.
2. Advantages of VEDAdeviceptr versus using raw pointers
One might think that it is disadvantageous to use a special pointer type in VEDA, however VEDAdeviceptr provides several advantages over using raw pointers.
2.1 Async malloc/free
VEDAdeviceptr allow asynchronous malloc and free. Let's take a look at the example shown in Listing 12.
| VEDAdeviceptr ptr; vedaMallocAsync(&ptr, sizeof(float) * cnt, 0); vedaLaunchKernel(func, 0, ptr, cnt); float* host = new float[cnt]; vedaMemcpyDtoHAsync(host, ptr, sizeof(float) * cnt, 0); vedaMemFreeAsync(ptr, 0); vedaCtxSynchronize(); // synchronizes computation with device |
This code only needs to synchronize once with the device. Listing 13 shows the same code using synchronous functions. Within only a few lines of code, we already double the number of device synchronizations.
| VEDAhmemptr ptr; vedaMemAllocAsync(&ptr, sizeof(float) * cnt); void* raw_ptr; vedaMemPtr(&raw_ptr, ptr); // synchronizes computation with device vedaLaunchKernel(func, 0, raw_ptr, cnt); float* host = new float[cnt]; vedaMemcpyDtoHAsync(host, ptr, sizeof(float) * cnt); vedaMemFreeAsync(ptr, 0); vedaCtxSynchronize(); // synchronizes computation with device |
The call to vedaMemPtr(...) needs to synchronize the execution with the device, because it needs to return the raw pointer to the application. For this, it needs to wait for the device to complete the allocation. This synchronization is not necessary when using VEDAdeviceptr, because it gets translated into the raw pointer on the device itself, which does not involve any communication with the host system.
2.2 Delayed Malloc
VEDAdeviceptr support delayed allocations. Let's assume we don't know how many elements our function will output, e.g., a kernel that filters values. In this case, we would need a code as shown in Listing 14, that first counts the number of output elements, transfers the number to the host, allocates the target buffer and then calls a second kernel.
|
// VE size_t count_output(VEDAdeviceptr indices_, const VEDAdeviceptr input_data_, const size_t input_cnt) { size_t* indices; float* input_data; vedaMemPtr(&indices, indices_); vedaMemPtr(&input_data, input_data_); return prefix_sum(idx, input_cnt, [input_data](const size_t idx) -> size_t { return input_data[idx] >= 3.14159; }); } void produce_output(VEDAdeviceptr output_data_, const VEDAdeviceptr indices_, const VEDAdeviceptr input_data_, const size_t input_cnt) { size_t* indices; float* input_data; float* output_data; vedaMemPtr(&indices, indices_); vedaMemPtr(&input_data, input_data_); vedaMemPtr(&output_data, output_data_); #pragma _NEC select_vector for(size_t i = 0; i < input_cnt; i++) { auto data = input_data[i]; if(data >= 3.14159) output_data[indices[i]] = data; } } |
In contrast, a code using delayed allocation requires significantly less interaction between host and device to achieve the same goal. This not only improves the performance, but also the simplicity of the code, as less variables need to be handled between host and device. Listing 15 shows the same code but using delayed allocation.
| // VE size_t produce_output(VEDAdeviceptr output_data, const VEDAdeviceptr input_data, const size_t input_cnt) { float* input_data; float* output_data; vedaMemPtr(&input_data, input_data_); vedaMemPtr(&output_data, output_data_); size_t* indices = new size_t[input_cnt]; size_t cnt = prefix_sum(indices, input_cnt, [input_data](const size_t idx) -> size_t { return input_data[idx] >= 3.14159; }); vedaMemAlloc(&output_data, sizeof(float) * cnt); #pragma _NEC select_vector for(size_t i = 0; i < input_cnt; i++) { auto data = input_data[i]; if(data >= 3.14159) output_data[indices[i]] = data; } delete[] indices; return cnt; } // VH VEDAdeviceptr output_data; vedaMemAllocAsync(&output_data, 0, 0); size_t cnt = 0; vedaLaunchKernelEx(produce_output, 0, &cnt, output_data, input_data, input_cnt); ... |
Despite that we only need a single kernel, indices is now a local variable, we need less than half calls to vedaMemPtr(...) within device code and don't need to synchronize in between the kernel calls, to wait for the number of output elements to get reported to the host.
3. Improving performance of Memset functions
VEDA provides memset functions for 8, 16, 32, 64 and 128-bit values. In early releases of VEDA, these have been naively implemented as simple loop (Listing 9). One exception was the 8-bit variant, which used the C function memset(...).
|
template void memset(T* dst, const T value, const size_t cnt) { #pragma _NEC select_vector for(size_t i = 0; i < cnt; i++) dst[i] = value; } |
As shown in Figure 1, the performance significantly differs significantly between the different bit sizes and is far from the theoretical peak performance and is far away from the theoretical peak bandwidth.
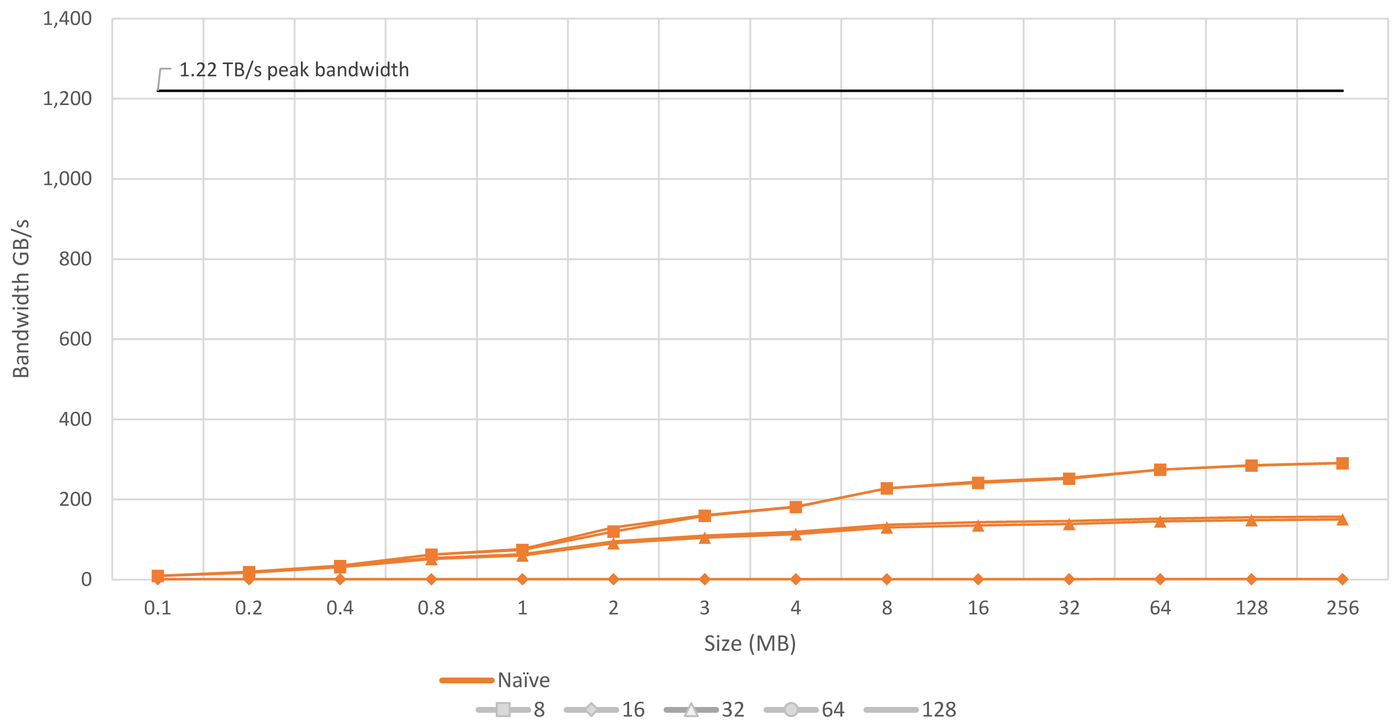
This is caused by multiple reasons:
- For the 32-bit case, vector-(un)packing causes unnecessary overhead for simple operations such as memset, resulting in lower performance compared to normally vectorized memsets.
- 16-bit values cannot be vectorized at all, resulting in extremely slow performance.
- 128-bit memsets require masking, as they write their values in an alternating order.
|
const int8_t vx[] = {value, value, value, value, value, value, value}; const int64_t v64 = *(const int64_t*)&vx; |
However, this cannot directly be applied to the destination pointer due to memory alignment. While 8-bit values require to be 1 Byte aligned, 64-bit values need to be 8 Byte aligned. Therefore we first need to use a sequential loop that sets all unaligned values. Second, we can set all values using a vectorizable data type. Third, we face the same problem at the end of the memset sequence, where we can have unaligned number of elements, that need to be set using a sequential loop. The code in Listing 11 shows the necessary changes.
|
template void memset_vectorized(T* dst, const T value, const size_t cnt) { #pragma _NEC select_vector for(size_t i = 0; i < cnt; i++) dst[i] = value; } template void memset_sequential(T* dst, const T value, const size_t cnt) { #pragma _NEC no_vector for(size_t i = 0; i < cnt; i++) dst[i] = value; } template void memset(T* dst, const T value, size_t cnt) { auto byte_offset = ((size_t)dst) % sizeof(int64_t); // set values sequentially until ptr is aligned auto alignment_cnt = (sizeof(int64_t) - byte_offset) / sizeof(T); if(alignment_cnt) { memset_sequential dst += alignment_cnt; cnt -= alignment_cnt; } // set values vectorized using 64-bit dtype
memset_vectorized dst += vector_cnt * items_per_iteration; cnt -= vector_cnt * items_per_iteration; } // set remaining items sequentially if(cnt) { memset_sequential } } |
With these changes we already achieve a great speedup as shown in Figure 2. For 16-bit it's up to 215x, for 32-bit it's 1.9x. The other memsets don't improve, as they have already been properly vectorized.
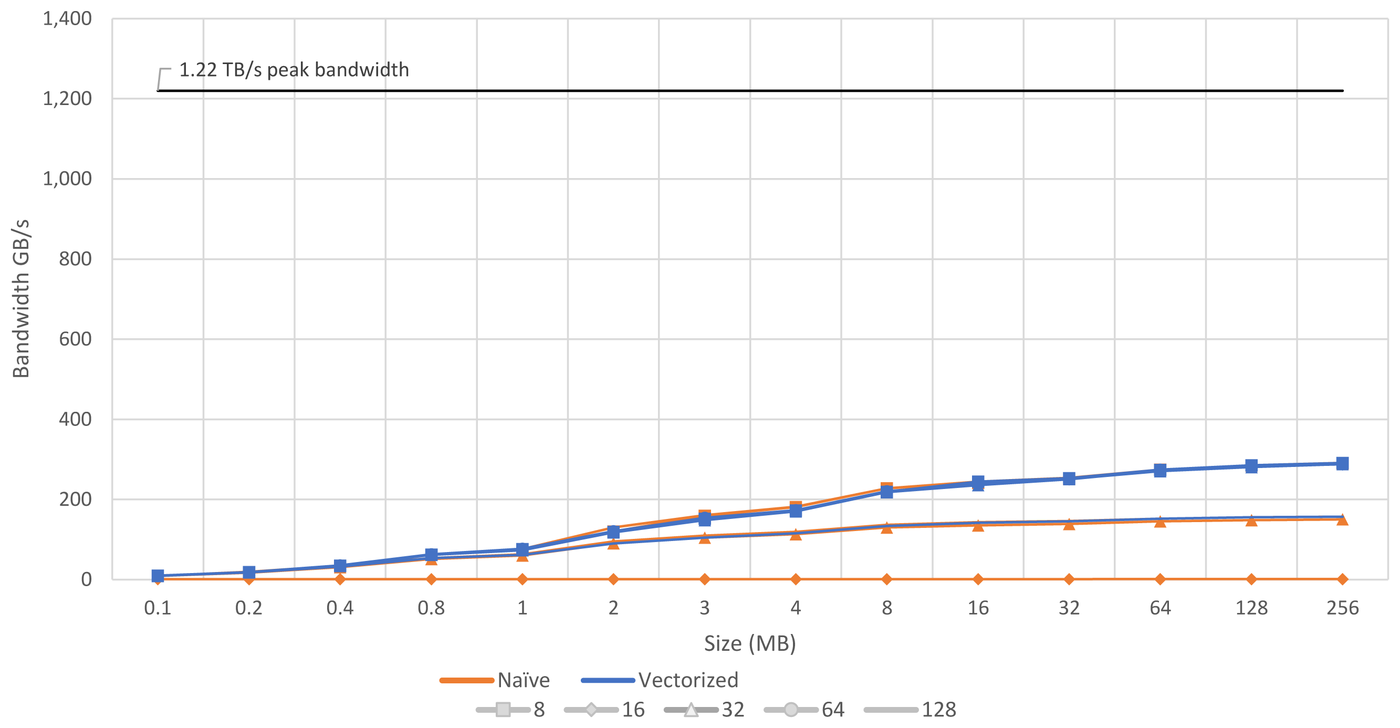
Figure 2: Performance comparison of properly vectorized to naive implementation of vedaMemset. We now achieve the identical performance irrespectively of the bit width, exception 128-bit which is caused by the masking necessary for these memsets.
However, this implementation still runs on a single thread. Especially for memsets of large arrays, using multiple threads can yield in much higher performance. But running on small memsets, it can have a negative impact to always utilize multiple threads. So we ran a series of experiments and identified that 2MB is the magic limit to switch from single- to multi-threaded. Figure 3 shows the final bandwidth we achieve using our optimized memsets.

Figure 3: Performance comparison of all optimizations for vedaMemset.
With these changes we finally achieve speedups of 2.8x for 8 and 64-bit, 595x for 16-bit, 5.3x for 32-bit and 3.3x for 128-bit, compared to our previous naive implementation.
4. Improving performance on Memcopy operations
In our last part of this article we take a closer look on how to the performance improvement on memcopy operations. We distinguish between four different types of memcopies:
- host to device (H2D)
- device to host (D2H)
- device to same device (D2sD)
- device to different device (D2dD)
4.1 Host to Device and Device to Host
H2D and D2H memcopies are based on the AVEO memcopy functions, that we have previously introduced in our article: AVEO-VEDA: Hybrid Programming for the NEC Vector Engine. As shown in the article, the AVEO implementation significantly outperformed the old VEO operations.
4.2 Device to same Device
The D2sD memcopies are running only on a single device and utilize the C++ function memcpy(dst, src, size);. However, when using multiple threads, as previously explained for memset, we can improve the performance up to 2.7x. For memcopy we also use the 2MB threshold.
4.3 Device to different Device
The D2dD memcopy poses a challenge for VEDA. As VEDA is based on AVEO, which does not provide a native method to copy data between two devices, we needed to implement this as a D2H followed by another H2D memcopy, which results in half of the peak memory bandwidth. To circumvent this problem, NEC's MPI in conjunction with AVEO introduced so called HMEM pointers, that allow to use these pointers together with NEC's MPI to copy data directly between different SX-Auroras. However, HMEM pointers are incompatible with VEDA's asynchronous memory allocation system, so we decided to introduce the VEDAhmemptr. This pointer can be used similarly to VEDAdeviceptr, but is primarily meant to be used for data exchange between different devices and other MPI-instances. By nature they are more prone to device synchronization, which is necessary for the device to device data exchange. In contrast, the VEDAdeviceptr are designed for more asynchronous execution on a single device.
Similar to VEDAdeviceptr, most of the helper functions for memcopy and memset are also available for VEDAhmemptr. To call a function with a VEDAhmemptr you either need to use vedaArgsSetHMEM(...) or just pass it as parameter to the C++ version of vedaLaunchKernel(...), which then will automatically convert it into a raw device pointer.
| VEDAdeviceptr | VEDAhmemptr | |||||
|---|---|---|---|---|---|---|
| When to use? | Data that stays on a single device, and that shall be executed as asynchronously as possible. | Data that shall be exchanged with other devices or MPI. | ||||
| Example Code |
|
|||||
| Properties |
|
|||||
4.4 Memcopy Performance
Let's take a look at the performance of the different variants of memcopy. Figure 4 shows our measurements for memcopies over the PCIE bus.
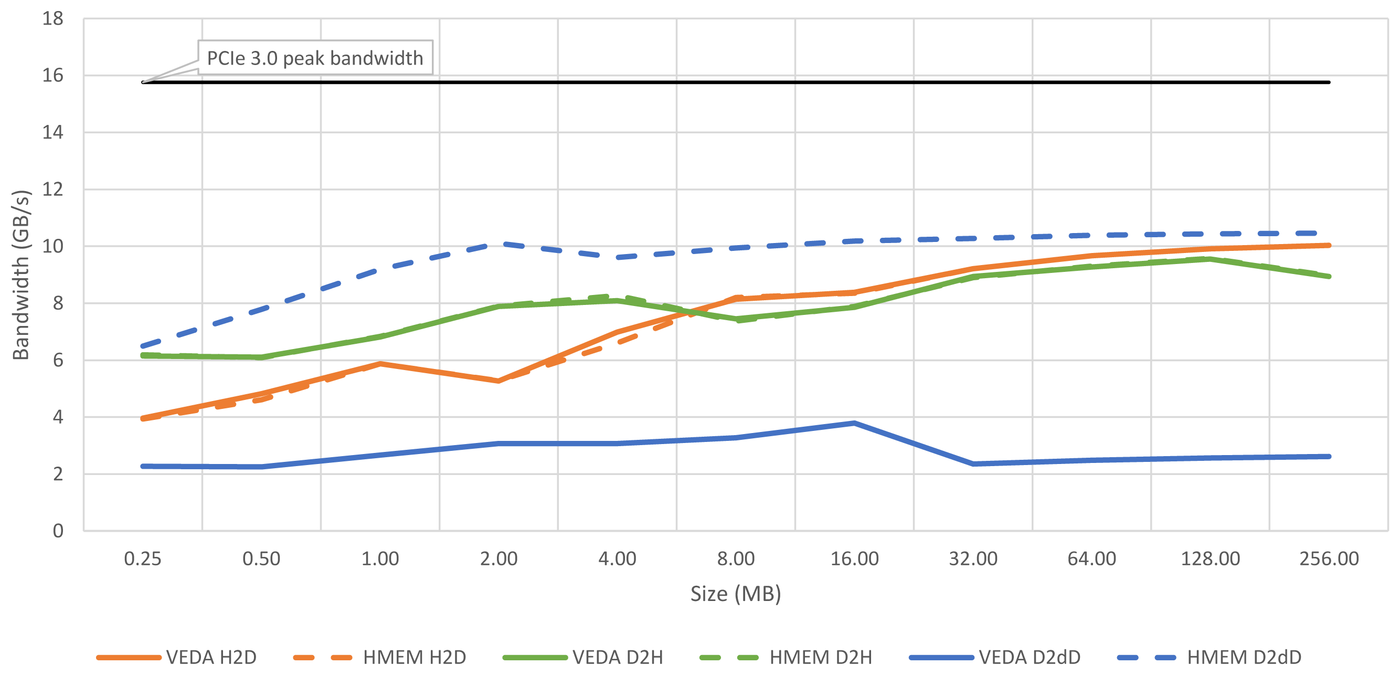
Figure 4: Performance comparison of different VEDA memcopy functions over PCIE.
As described before, VEDA's D2dD copies the data to the host first, and therefore achieves only very low memory bandwidth compared to D2H and H2D copies.
For H2D and D2H it's independent if they are used with VEDAdeviceptr or VEDAhmemptr.
In Figure 5 we show the achieved bandwidth for memcopies running on the same VE.
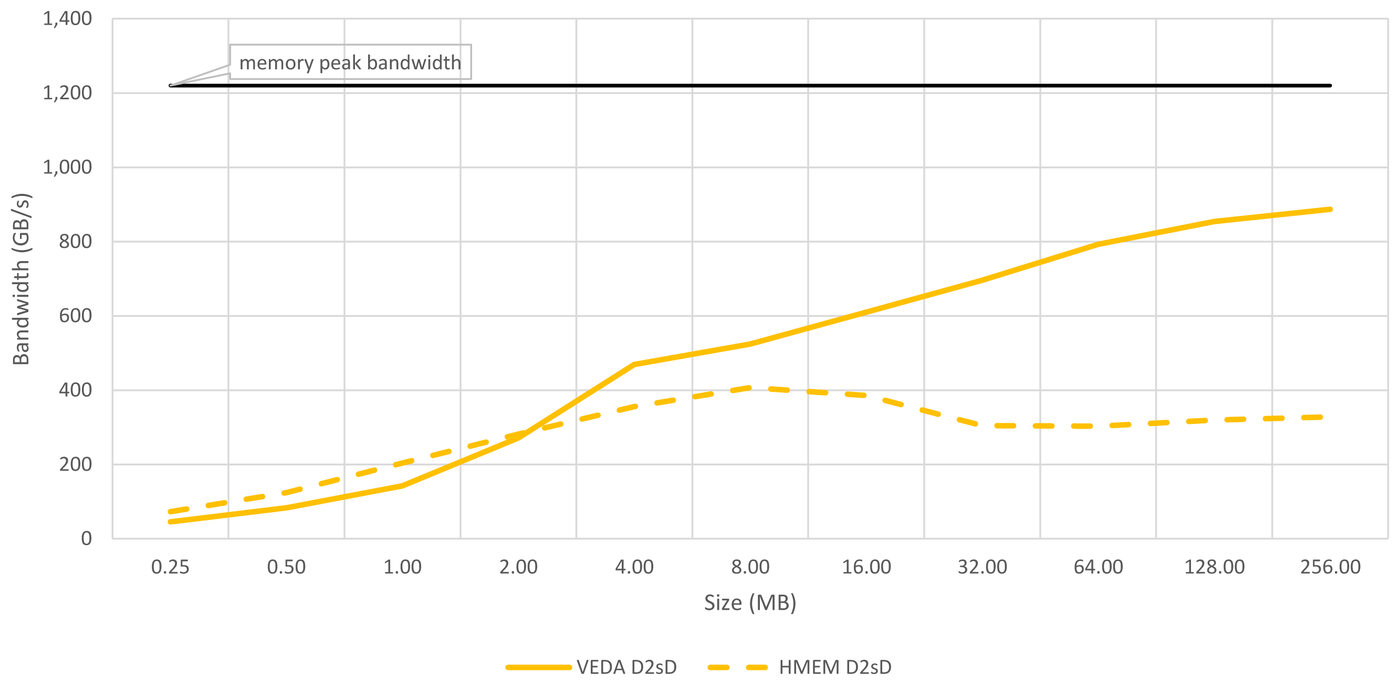
In these D2sD case we see that using VEDAhmemptr yields in better performance for smaller sizes, while VEDAdeviceptr yields in better performance for larger sizes. This is caused by two effects: First, VEDAhmemptr uses AVEO's veo_hmemcpy, which is a lower-level function with less overhead compared to VEDA-based kernels, that yields in lower latencies for small sizes. But for larger memcopies VEDAdeviceptr memcopy makes better use of multi-threading.
These results underline our previous recommendations, that if you want to share data between different devices, it's better to use VEDAhmemptr and VEDAdeviceptr if you want to keep data on a single device.
Summary
In this article we explained several ways how to use C++ functions overloading and templates within VEDA and how we improved memset and memcopy performance within VEDA using different techniques. All presented optimizations are available in upcoming VEDA release. If you want to experiment with these optimizations before the official release in VEOS, you can use the v1.4.0 release from Github.